
GCP's Dataflow is a really powerful weapon when you need to manipulate massive amounts of data in a highly parallel and flexible fashion. Dataflow pipelines surely are the number one asset in every GCP data engineer toolbox.
However, learning to use Apache Beam, which is the open source framework behind Dataflow, is no bed of roses: The official documentation is sparse, GCP-provided templates don't work out-of-the-box, and the Javadoc is, well, a javadoc.
In this series, I would like to present you some of the trickiest issues Dataflow and Beam had in store for me, and how I overcame them.
Let's start with a bit of BigQueryIO frustration...
How to write data to dynamically generated BigQuery tables ?
Beam provides the ability to load data into BigQuery using dynamic destinations, where the target table spec is derived dynamically from incoming elements. We would like to use this feature to achieve the following design

Events coming from several Kafka topics are handled by a single Dataflow pipeline then serialized to several BigQuery tables: events from topic A go to table A, and so on...
Luckily, there is a solution to this exact problem offered in Beam Javadoc
A common use case is to dynamically generate BigQuery table names based on the current value. To support this, BigQueryIO.Write.to(SerializableFunction) accepts a function mapping the current element to a tablespec. For example, here's code that outputs quotes of different stocks to different tables:
PCollection<Quote> quotes = ...;
quotes.apply(BigQueryIO.write()
.withSchema(schema)
.withFormatFunction(quote -> new TableRow()...)
.to((ValueInSingleWindow<Quote> quote) -> {
String symbol = quote.getSymbol();
return new TableDestination(
"my-project:my_dataset.quotes_" + symbol, // Table spec
"Quotes of stock " + symbol // Table description
);
});
Unfortunately, when we implemented this stage in our pipeline, with a CreateDisposition of BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED, we soon found out that only the first dynamic table of the pipeline output had been created. The other tables were missing, and as a result the data loading failed. This is a known bug in Beam, which has been around for more than 2 years.
Facing this issue, we had no other choice than to develop a workaround.
Custom table-creation stage
Apache Beam is an extensible framework, and as such it is possible to develop a new transformation stage, aka PTransform. Therefore, we developed a PTransform whose single goal is to check if the target table of incoming elements exists, and create it if not.
For this we have to bypass BigQueryIO and use the BigQuery java client directly. The client should be instantiated during the setup or startBundle phase of the PTransform:
import com.google.cloud.bigquery.*;
...
@Setup
public void setup() {
this.bigquery = BigQueryOptions.getDefaultInstance().getService();
}
With the client, we can easily call api methods to create tables. But, not so fast: we can't check tables for each element, it would not be sustainable. On the contrary, we have to group elements by lot and check for each lot. Within a streaming pipeline, grouping means windowing. A simple strategy with fixed windows is enough for this:
input.apply(Window.into(FixedWindows.of(Duration.standardSeconds(15l))))
Fixed windows of 15 seconds' width
Then we just have to inspect the content of each window and group their elements by target table name
input.apply("Compute target table name", WithKeys.of(new GetTargetTableName(this.outputTableSpec))).apply(GroupByKey.create())
Now it's possible to check the table for each group. But no need to check repeatedly for the same table name every 15 seconds : let's use some caching, for example Guava Cache. That way we minimize costly api calls
input.apply("Create target table if needed", ParDo.of(new CreateIfNeeded()))
To see the details of CreateIfNeeded and the rest of the implementation, check out this Gist
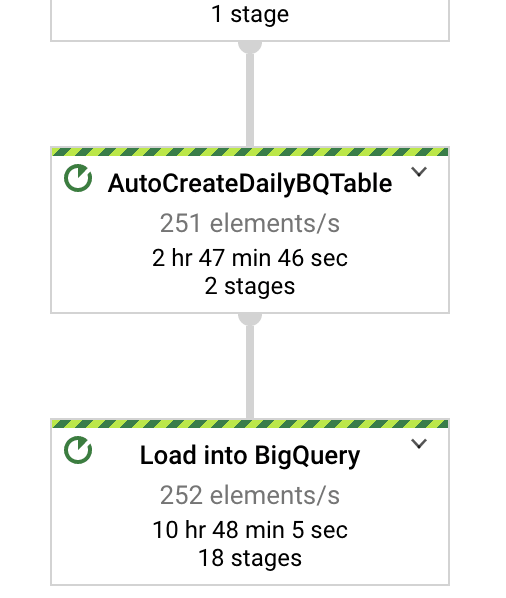
Finally we can have the satisfaction to watch our nice stage deployed, just before BigQuery.Write who can safely load data into sure-to-exist tables
See you soon for the next Dataflow tricky trick !


















