
そして同様に重要なのは、ストレージ・ノードが故障した時や、システムをスケールアップするために新しいストレージ・ノードを追加した時にどうなるかだ。 ハッシュは、このようなシナリオでデータの保存場所を決定するための一般的かつ効率的な方法であり、何らかのデータ・ストリーミング・アプリケーションを実装している場合は特に理解しておく必要がある。
ハッシュとは何か?
ハッシュは、ファイルや任意の文字列のような可変サイズのデータを、一貫性のある固定サイズの出力に変換するために、「ハッシュテーブル」と「ハッシュ関数」またはアルゴリズムを使用します。
ハッシュ関数(または一貫性のあるハッシュ・アルゴリズム)とは、データを受け取り、そのデータを表す数値を出力する数学的演算であり、その数値は、提供されたデータの元のサイズよりもはるかに小さい。 ハッシュ関数によって出力される数値は「ハッシュ」と呼ばれ、その値は、同じデータでハッシュ関数が呼び出されるたびに一貫性を持つ。そして、ハッシュテーブルでデータを検索することができる。
非常に単純な例として、モジュロ演算子(%)をハッシュ関数として考えてみよう。 モジュロ演算子に与えられた数値の大きさに関係なく、[データ] mod nに対して、指定された範囲n内で一貫した数値を返す:
69855 MOD 10 = 5
63 MOD 10 = 3
916 MOD 10 = 6
26666 MOD 10 = 6
最後の例は、異なる入力が同じハッシュ値6を返す「衝突」を示している。また、ハッシュ関数を調整することで、例えばx MOD 20や x MOD 30のように出力範囲を変更できることもわかる。
実際のハッシュ実装では、予想される入力データに応じて、衝突を処理し、メモリを最も効率的に使用するために、より複雑なハッシュ関数が使用される。
なぜハッシュを使うのか?
ハッシュの一般的な例は、データの保存と検索である。 例えば、150億のアイテムのコレクションがあり、特定のアイテムを検索する必要があるとしよう。 どのようにするのだろうか? ひとつのメカニズム的な方法は、データセットを繰り返し処理することだが、これはキー・バリュー・ストアのキーの数が増えるにつれて非効率的になる。
これは次のように動作する:
データ・アイテムを格納するとき、まずデータに関連するキーをハッシュ関数に通します。 その結果得られたハッシュに基づいて、ハッシュされた位置のハッシュ・テーブルにデータを格納します。 衝突が発生した場合、データが失われないようにするための手段を講じる必要があります。たとえば、ハッシュ・テーブルにはデータそのものではなくデータのリンクされたリストを格納したり(チェーン・ハッシュとして知られています)、ハッシュ関数が空のスロットを見つかるまで探し続けたりします(プロービングやダブル・ハッシュなどのテクニックがあります)。
データ・アイテムを取り出すときは、データに関連づけられたキーをハッシュ関数に通し、その結果のハッシュ・コードをハッシュ・テーブルで調べる。
すでにデータのキーがあるのなら、そのキーを直接使ってデータを格納すればいいじゃないか。 例えば配列のインデックスとして。 それは可能だが(これは何もしないハッシュ関数を使うのと同じことだ)、非常に効率が悪い。 キーが非常に大きく、連続していない場合はどうすればいいのだろう?
分散システムでのハッシュ
前の例では、ハッシュテーブルを使って大きなデータ項目のリストを保存したり取り出したりすることを説明したが、そのリストが物理的に複数のサーバーに分散している場合はどうだろう?
分散システムでは、ハッシュ関数を使ってデータの保存場所を決めることができる。 先ほどの例のように、ハッシュ関数がハッシュテーブルの場所を指す代わりに、分散システムでは別のハッシュ関数を使うことができる。
例えば分散システムにデータを保存する場合、まずデータに関連するキーをハッシュして、データが保存されるべきサーバーIDを生成し、そのサーバーにデータを保存する。 出力が利用可能なすべてのサーバーに一様に分散されるハッシュ関数を選択した場合、どのサーバーも過負荷にならず、データを素早く取り出すことができる。また、サーバーの負荷を分散するためにサーバーの数を増やすという、同様の方法で負荷分散を 考えることもできる。
この例では、データのキーのハッシュに基づいて、データを保存するサーバーを決定します:
保存するデータのキーを表すハッシュコードを生成する。結果として得られるハッシュコードは1から5の範囲に入るはずである(サーバーが5つあるため)。
先ほどの例では、ハッシュ関数に非常に単純なモジュロを使ったが、ここでのハッシュ関数は「
[key] MOD 5」と考えればよい。IDが計算されたサーバーにファイルを保存する。
これはうまくいきますが、サーバーがダウンした場合はどうなるのでしょうか? 新しいサーバーが追加された場合はどうなるのでしょうか? いずれの場合も、すべてのデータはハッシュを再計算し、新しいハッシュの結果に基づいて移動する必要があります - リハッシュとして知られていますが、これは非効率的であり、上記のアプローチが本番で使用するには単純すぎる理由です。
一貫性のあるハッシュとは?
一貫性のあるハッシュは、分散システムにおいてデータがどこに保存されるべきかを決定し、サーバーの追加や削除を許容することで、インフラストラクチャの変更時に移動または再ハッシュが必要なデータ量を最小限に抑えます。
一貫性のあるハッシュとハッシュの違い
ハッシュ化とは、可変量のデータをハッシュ・テーブルとして知られる一貫性のある固定サイズのストレージ構造に格納し、迅速かつ効率的に検索できるようにする一般的な手法です。 選択されるハッシュ・テーブルのサイズは、格納されるデータの量や、利用可能なシステム・メモリなど、より実用的な考慮事項によって異なります。 ハッシュ・テーブルのサイズが変更されると、通常、ハッシュ関数も変更され、データが新しくサイズ変更されたテーブルに均等に分散されるようになります。
コンシステント・ハッシングは特殊なハッシングで、ハッシュ・テーブルのサイズが変更されたとき、移動が必要なデータはごく一部に限られる。 具体的には、移動が必要なデータ項目の数はn/mであり、nはデータ項目の数、mはハッシュ・テーブル(先の分散システムの例ではサーバー)の行数である。
一貫性のあるハッシュの仕組み
一貫性のあるハッシュでは、データを保持するサーバ(または任意の仮想ノード)が円形に配置され、時計回りに番号が振られていると想像してください。 物事をより直感的にするために、ほとんどの図ではノードに1から360(度)まで番号が振られていますが、実際に選ばれた番号や、それらが連続しているかどうかは重要ではありません。重要なのは、あるサーバから別のサーバへ時計回りの方向で円の周りをたどるときに、割り当てられたサーバIDが昇順になることです。次のノードのIDは、周回するまで常に前のノードより大きくなります。
どのサーバーにデータを保存すべきかを決定する際には、データのハッシュを計算し、そのハッシュのモジュラスを360とします。 結果の数字は、おそらく有効なサーバー番号とは正確に一致しないので、結果の数字に最も近く、結果の数字よりも大きいサーバーIDが選択されます。 結果の数字よりも大きいIDを持つサーバーがない場合は、0に戻ってサーバーIDを探し続けます。
例として
あるデータキーが存在し、それにハッシュ関数が適用され、その結果が5562であったとする。
5562 MOD 360は162である。
IDが162より大きく、162に最も近いサーバ(たとえば、下図のID 175)を配置から見つけます。

サーバーが360台ない場合、または360台以上ある場合はどうなりますか? 数は重要ではなく、原理だけが重要です。 選択されたサーバーIDに昇順で番号が付けられ、適度に等間隔で、概念的にリング(ハッシュリングとして知られている)に配置されている限りです。
なぜ一貫性のあるハッシュを使うのか?
データが複数のノード(またはサーバー)に分散しているため、ノードの追加や削除が非常に効率的になります。 IDが90、180、270の3つのノード、A、B、Cがある場合を例に考えてみましょう。 このセットアップでは、各ノードにデータの3分の1が格納されています。
新しいノードDを追加したい場合、新しいID、例えば360を割り当てます。
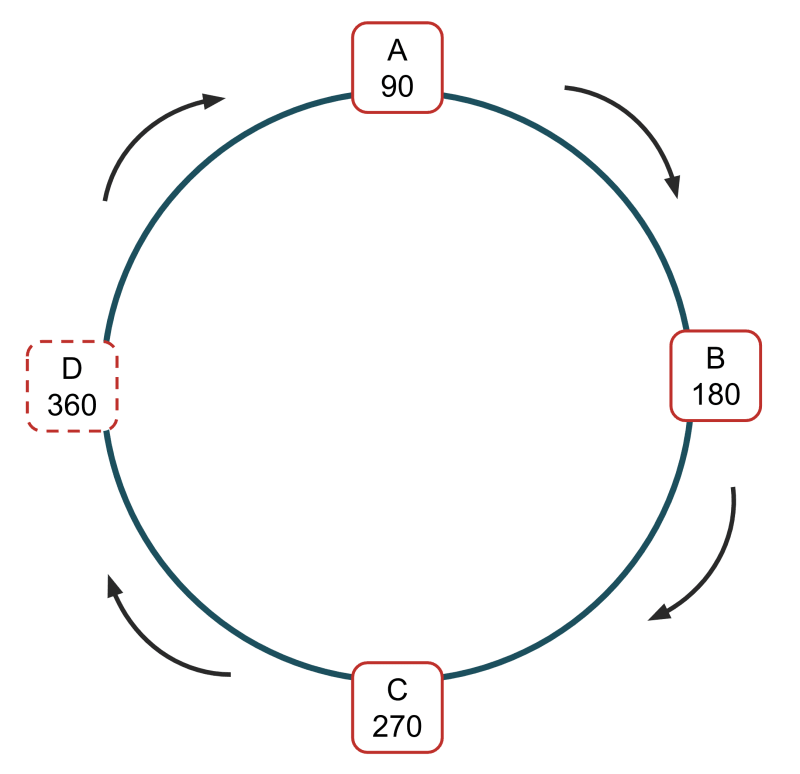
どちらの選択をするかは、実装されているソリューションに依存します。ウェブ・キャッシングやキャッシュ・サーバーの実装では、前者を行い、キャッシュ・ミスがDにゆっくりと入るようにします。他のソリューションでは、Aからデータの半分を取り出し、Dに転送します(あまり深く数学に立ち入らずに説明すると、転送されるデータは、新しいデータであればDに格納されるハッシュ値を持つ必要があります)。
一貫性のあるハッシュ・ベースのネーミング・サービスとは?
この投稿の前の例では、データまたはファイルをサーバに格納することを考えてきましたが、この原理はあらゆるデータを分散して格納することに拡張することができます。 ネーミングサービスは、作成されたシステムの中で最大かつ最も分散したシステムの1つであり、一貫性のあるハッシュを使用して実装するのに適しています。 特定の異なる実装を持つDNSはひとまず置いておくとして、一貫性のあるハッシュを使用した、より一般的なネーミングサービスは以下のように実装できます:
命名レコードは複数のサーバーにまたがって保存される。
ネーミングレコードは複数のサーバーにまたがって保存される。サーバーにはIDが割り当てられ、概念的なリングの中で昇順に並べられる。
名前を解決するには、名前レコードが格納されているサーバーを特定しなければならない。
名前のハッシュをとり、その結果のモジュラスを360とする(サーバーの数が360未満であると仮定する)。
そのようなサーバーが存在しない場合は、IDが最も小さいリングの最初のサーバーを探す。
名前レコードは、特定されたサーバーで見つかる。
似たような方法で動作するコンテンツデリバリーネットワークも考えることができ、ホットスポットを避けるために異なるノード間でリクエストのバランスをとる。
一貫したハッシュの実装
JavaからPythonまで、複数のノードが分散ハッシュテーブルを含む一貫性のあるハッシュリングに配置されている既存の実装がGithubに複数存在する。
Redis、Akamai、Amazonのdynamoなど、一貫性のあるハッシュを使用するプロダクション・ストレージ・システムが存在し、その多くはデータ検索の最終ステップにmemcache、バイナリ検索、ランダムツリーなど、より複雑なデータ構造を使用する。
一貫性のあるハッシュを実装する手順
基本的なテクニックを説明したところで、一貫性のあるハッシュ・ソリューションを実装し始めることができますが、以下のことを考慮する必要があります:
あなたのソリューションには何台のサーバがありますか?
どのようにサーバIDを割り当てるのか。
データ・ハッシュの作成にどのハッシュ関数を使用するか。 データが単一のサーバーに集中せず、すべてのサーバーに均等に分散されるように、均一な出力を生成する関数を選択したい。
データをクラスター化させないために、サーバーIDをできるだけ等間隔に保つようにしましょう。
一貫したハッシュの実装例
ファイルが5台のサーバーのいずれかに保存されている例を考えてみよう。 サーバーIDは1~360の間で割り当てる。
サーバーは概念的なリング状に配置され、74、139、220、310、340のIDが割り当てられる。
新しいファイルを格納する必要があるので、このファイルのキーをハッシュし、その結果を1551とする。
1551 MOD 360を実行すると、111となる。
したがって、データファイルはID 139のサーバーに格納される。

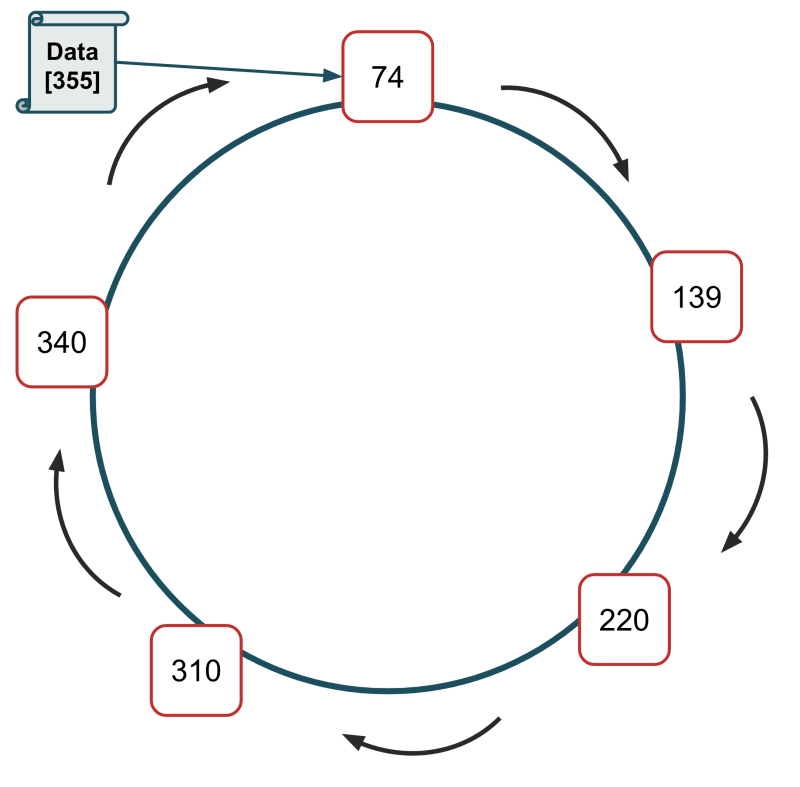
別の例を考えてみよう:
サーバーは概念的なリング状に配置され、74、139、220、310、340のIDが割り当てられている。
新しいファイルを保存する必要があるので、このファイルのキーをハッシュすると、結果は1075となる。
1075 MOD 360を実行すると、355となる。
355を超えるサーバーIDはないので、データファイルはID 74のサーバーに保存される。
一貫したハッシュの最適化
一貫性のあるハッシュを使用しているシステムでノード(サーバ)が故障した場合、設計上、すべてのデータはリング内の次のサーバに再割り当てされる。 これは、故障したサーバが次のサーバの負荷を倍増させることを意味し、よくても負荷の高いサーバのリソースを浪費し、最悪の場合、カスケード障害を引き起こす可能性がある。例えば、あるサーバーが4つの可能なハッシュを持ち、リングの4つの場所に存在するとします。このサーバーが故障した場合、このサーバーに保存されているデータは4つの異なる場所に再配布されるため、他のサーバーの負荷がさらに4分の1を超えることはなく、より管理しやすくなります。
PubNubによる一貫したハッシュの実装
PubNubは、アプリケーションが大規模かつグローバルな規模でメッセージを配信できるようにする開発者向けAPIプラットフォームです。 PubNubには複数のポイントが存在するため、安全、確実、迅速にメッセージを配信できます。
顧客が期待するスケールと信頼性を提供するために、一貫したハッシングを含むいくつかの技術をバックエンドで使用しています。
クライアント間、またはクライアントとサーバー間で大規模にデータを交換する必要があるアプリケーションを作成している場合、どのハッシュ機構を使用するかだけでなく、考えることがたくさんあるでしょう。 PubNubに通信のニーズをすべて任せておけば、ビジネスロジックに集中でき、アプリのスケールに伴う低レベルのデータ伝送を心配する必要はありません。
エッジコンピューティングを検討している場合は、エッジメッセージバスソリューションをご覧ください。また、PubNubが通信と ブロックチェーンWeb3ソリューションをどのようにサポートできるかをご検討ください。
PubNubは無料でお試しいただけます。サインインするか、無料アカウントに登録するだけで、アプリを作成したり、PubNubがどのようなものかを確認するツアーを体験できます。


















