選定理由
生成モデルである大規模言語モデル(LLM)で系列ラベリング問題である固有表現認識(NER:Named Entity Recognition)を解くという視点を知りたい。LLMが今後増えるにつれて識別タスクへの活用も求められる。
Paper: https://arxiv.org/abs/2304.10428
Code: https://github.com/ShuheWang1998/GPT-NER
概要
【社会課題】
LLMがトレンドであるが、生成系タスクだけでなく識別系タスクの需要もある。特にLLMに蓄積された膨大な知識を活用できるメリットは大きい。
【技術課題】
LLMは生成系モデルであり、系列ラベリング問題のような識別系タスクを解くためのモデルとは扱い方が異なる。
【従来技術】
ACE[Wang2021]等TransformerベースのNERを解く識別モデルがある。一般的に生成モデルは識別タスクにて十分な精度を達成できない。
【提案】
エンティティを表す特別なインジケータ(@@##)を導入することでNERを生成タスクに変換したGPT-NERを提案。さらに、生成されたテキストをLLMに再度問い合わせるというself-verificationを行うことで hallucination(オーバーフィッティングの1種)を軽減する提案をした。
【効果】
NERベンチマーク向けデータセット5種類で評価した結果、SOTAの識別モデルに匹敵する精度をGPTで達成することができた。又、self-verificationは正則化項として機能することでhallucinationをある程度を抑えることができた。
GPT-NER + self-verification
本来、識別タスクである固有表現認識(NER)をどうやって生成タスクとして捉えるかの説明。

Prompt Constructionの工夫によってタスク変換を行う。Promptの構成は図1のような3要素からなる。注意点として Few-shot Demonstration では1つのエンティティラベルごとに1プロンプトを与える(図1の例では3プロンプトに分けている)。これはNクラス分類をN次元のバイナリ分類に変換しているに等しい(らしい)。こうすることでGPTのプロンプト長制約を受けないようにしている。又、エンティティがないような文では、特にエンティティインジケータを付与しない文を与える。最後の入力プロンプトは青い枠のInput Sentenceで Output: の後をブランクで入力すると緑の出力文が生成される。
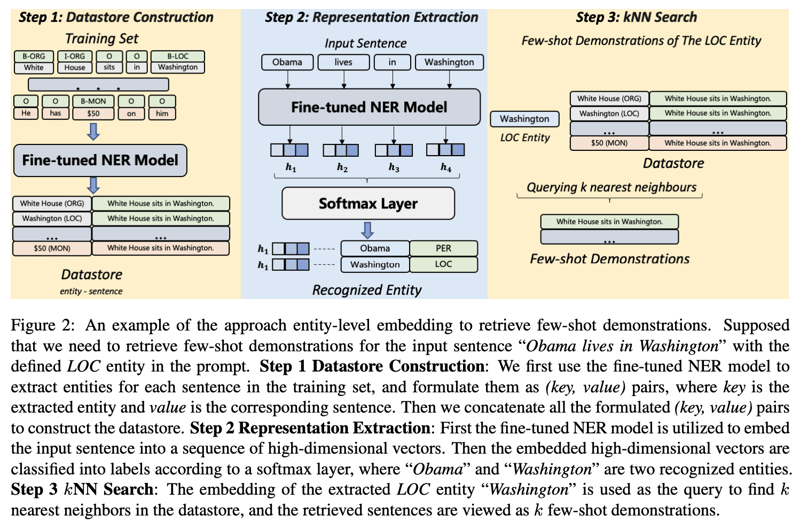
few-shotで入力する文章の選定は重要であるが、入力文に近いコンテキストである方が精度が高い。そこで入力文に近いコンテキストのfew-shotをいかに選択するかが、図2で説明しているDemonstrations Retrievalである。最初に事前学習ずみNERモデルを用いてDatasetの構築を行い、この中から入力文のテキストの埋め込みベクトル、もしくはエンティティの埋め込みベクトルに近いものを検索し、few-shotの文として選択する。

self-verificationは生成時の文章と回答をそのまま入力し、正しいかどうかを検証させるプロセスである。ここでも先ほどと同じような構成でプロンプトを作成する。
実験
GPT-3バックボーン、davinci003をモデルパラメータに使用、トークン最大長は512にした。
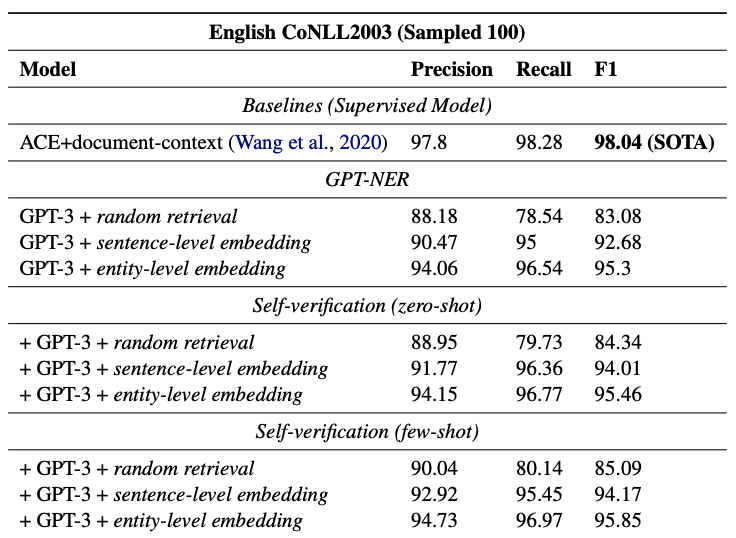
識別モデルのSOTAであるACEに迫る結果となった。entity-level embeddingが最も性能が良く、self-verificationも微増させた。
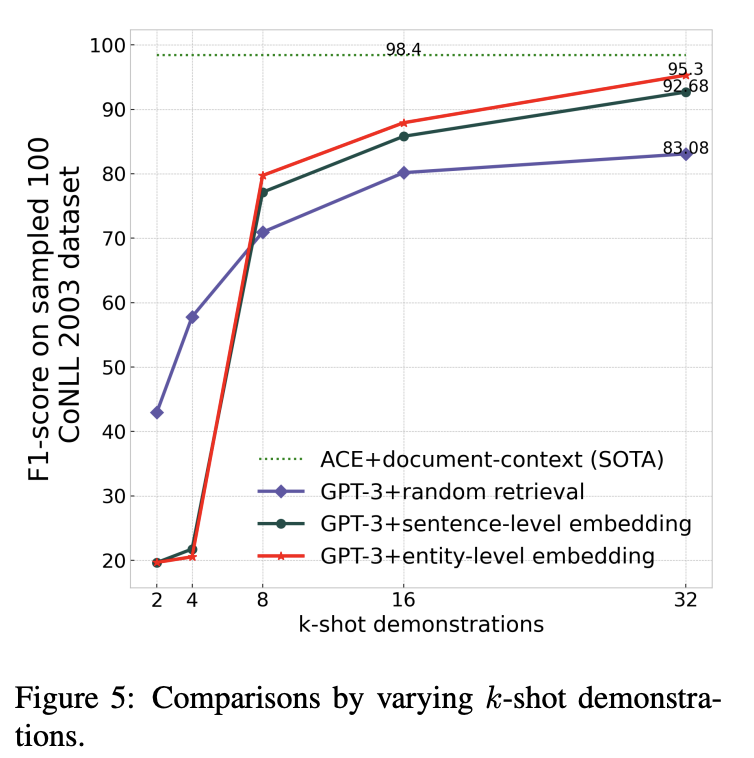
図5はshot数に関する実験で、32-shotくらいで飽和してくる(あくまでGPT-3の話)。shot数が極端に少ない場合はフォーマットに従わない出力が多かった(パースできないため誤りとカウントされる)。
エンティティトークンの選定は非常に重要らしく、以下のBMES, Entity+Positionで 32-shot 試したが、どちらも@@##よりも大幅に精度低下した。
BMES
Input:White House is in Washington
Output:B-ORG E-ORG O O O
Entity+Position
Input:White House is in Washington
Output:White House (0)
BMESはトークン列が長い場合にエラーが多く、Entity+Positionは位置の誤りが多かった。LLMは数値演算に弱いためと考えられる。


















