選定理由
LLMの発展によってデータアナリストの仕事が消滅するのでは?という懸念から。
Paper: https://arxiv.org/pdf/2305.15038.pdf
Code: https://github.com/DAMO-NLP-SG/GPT4-as-DataAnalyst
Data-Copilotの論文[Zhang2023]でCitationされている。
概要
【社会課題】
データアナリストはビジネスパートナーの要求に基づいてデータベースから関連データを抽出し、理解しやすい形で可視化し、解析結果に対する考察を提供するという比較的定型業務が多い。そのため、LLMの能力が向上するにつれてデータアナリストという職業がAIで代替される懸念があり、大衆の注目を集めている。
【技術課題】
ビジネスクエスチョンに応じてデータベースのどの項目を取得し、どのような可視化を行うことがレポート作成に効果的であるかはドメイン知識が必要となる。e.g. サーバがなぜダウンしたか?という問いに対してはトラフィックのバースト検出の可視化等が効果的である。
【提案】
データスキーマとビジネスクエスチョンを入力とし、データアナリストの分析レポートをエンドツーエンドで出力させるフレームワークを提案した。ビジネスクエスチョンはLLMが持つ高い意図理解能力・ドメイン知識により、適切なデータ抽出処理、可視化処理、レポート生成処理が自動的に実行される。
【効果】
成果物としてのレポートはジュニアアナリストの品質よりも良く、シニアアナリストに匹敵することが確認された。コストと時間についてはもちろん比較にならないほどGPTが優位である。
GPT-4 as a data analyst
3つのステップがある:(1) コード生成(青い矢印)、(2) コード実行(オレンジの矢印)、および(3) 分析生成(緑の矢印)。システムへの入力としてはビジネスクエスチョン(自然言語)とデータベーススキーマ(テキストデータ)のみである。

(1)コード生成では、セキュリティのためデータスキーマのみがGPTに提供される。GPTはテーブル1に示すようなプロンプトを受けて複数のデータベーステーブル間の関係を理解し、必要なクエリ及びpythonコードを生成する。(2)データの安全性を維持するため、コードとクエリ実行はオフラインで実行される。結果としてチャートのpdfファイルと取得したデータのtxtファイルが得られる。

(3)テーブル2に示すプロンプトを用いて、データ分析が元のクエリと整合していることを確認するために、質問と抽出されたデータの両方を入力として使用する。抽出されたデータに関する説明の段落を生成する代わりに、GPT-4に対してキーポイントを強調する5つの要点で分析と洞察を生成するように指示する。予備的な実験から、GPT-4は図を見ずにデータ自体からトレンドや相関を理解することができるとわかっている。
実際のデータアナリストの役割では、関連するビジネスの背景知識が必要な場合があるため、外部の知識源(例:Google)からリアルタイムのオンライン情報(I)をクエリするための外部知識検索モデルg(·)を設計した。このオプションでは、GPT-4はデータ(D)とオンライン情報(I)の両方を入力として受け取り、分析(A)を生成する。
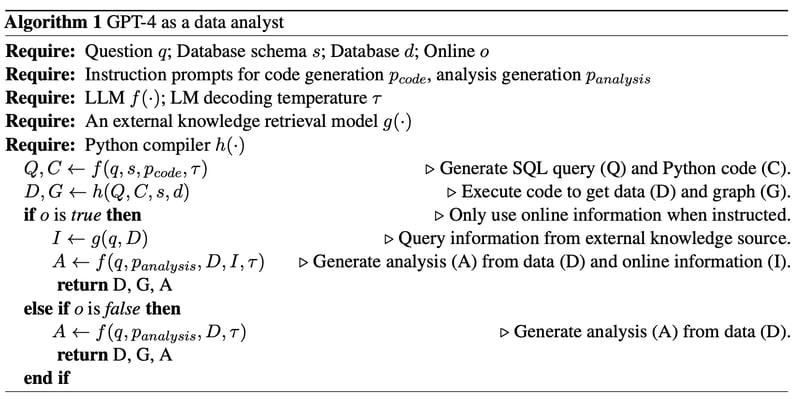
提案するアルゴリズムの全体像は上記のようになる。
実験
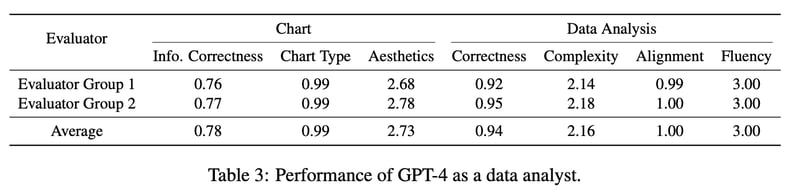
「NvBench」データセットの様々なドメイン、チャートタイプ、難易度の質問から、100の質問をランダムに選択。チャートは棒グラフ、積み上げ棒グラフ、折れ線グラフ、散布図、グループ化散布図、円グラフをカバーしている。難易度は簡単、中程度、難しい、非常に難しいの4種、ドメインにはスポーツ、アーティスト、交通、アパートの賃貸、大学などが含まれている。レポートは5つの要点で記述し、評価指標を使用して品質を評価した。チャートはinformation correctness, chart type correctness, aestheticsで評価、文章はcorrectness, alignment, complexity, fluencyで評価した。なお、NvBenchから抽出した想定ビジネスクエスチョンは実際の業務に比べると実践的でない面があり、GPT-4でアナリストが代替されるかは更なる検証が必要である。
表3では、データアナリストとしてのGPT-4の性能が200のサンプルで評価した。chart type correctness, aesthetics に関しては高いが、information correctnessには改善の余地がある。文章評価に関してはGPT-4は平均してalignmentとfluencyで高スコアであった。correctnessスコアはチャートのcorrectnessよりも高かった。これは興味深く、生成された図表が間違っていても、文章は正しい場合があることを示す。先述したように、生成された図表は大部分が正しい図表と一致しているため、一部の箇所のみが誤っている。complexityスコアに関しては、平均して3点満点中2.16点と十分な結果であった。
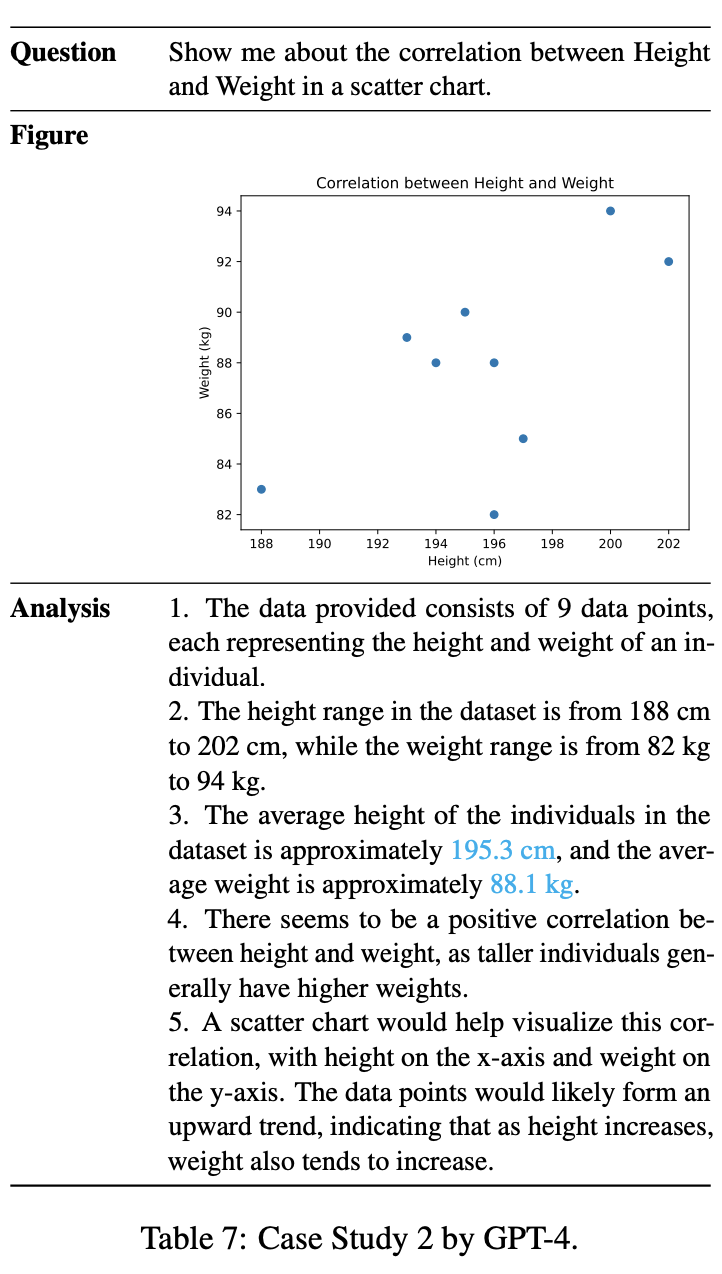
生成されたレポートのサンプルがテーブル7である。適切なデータを抽出、チャート、レポートの作成ができている。以前から言われているが、複雑な数値演算に弱い側面が見られた。
アナリストとGPT-4の成果物の差として、1つはGPT-4の hallucination のような誤りがあり、アナリストはこのようなエラーは避ける。2つ目にアナリストは分析前の前提条件となる事を把握しているが、GPT-4は(プロンプトで与えない限り)全てを把握しているわけではない。


















