選定理由
CoT,CoT-SC の強化学習的一般化、langchain等ライブラリにもすでに実装例あり。Googleの研究チーム、ICLR2023採択
Paper: https://arxiv.org/abs/2210.03629
Code: https://react-lm.github.io/
CoTについてはこちらのブログを参照するとよい。
概要
【社会課題】
従来の大規模言語モデル(LLM)は、言語理解や対話型意思決定のタスクにおいて圧倒的なパフォーマンスを示してきたが、推論(reasoning)と行動(action)の組み合わせに関する能力は別々のトピックとして研究されてきた。このため、思考連鎖推論(chain-of-thought prompting[Wei2022])や行動計画生成[Ahn2022]などの能力を統合的に活用することにより、LLMのパフォーマンスと人間の解釈可能性、信頼性の向上が可能であるかは未解明である。
【技術課題】
推論と行動の相互作用によるシナジー効果やその応用範囲については未知。従来手法では(通常のCoTの)内部表現に基づく静的な推論では外部の情報に対応しづらく、ハルシネーションやエラー伝播といった問題がある。さらに、言語モデルを使用した意思決定や行動計画においても、高次の目標の抽象的な推論や作業メモリの管理法も提案されていない。
【提案】
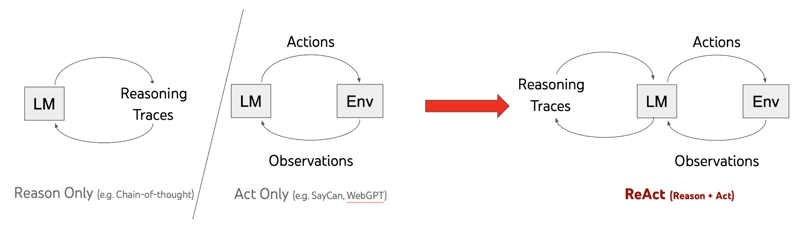
LLMを用いて推論とタスク固有のアクションを交互に生成することで、推論と行動の動的統合を実現するReActを提案した。これにより、モデルは高次の計画を作成し、維持、調整するための推論を行いながら、外部環境とのインタラクションを通じて追加情報を組み込むことが可能となる。
【効果】
ReActは質問応答や事実検証のタスクにおいて、CoTと比較して幻想やエラー伝播の問題を解決し、推論過程がより解釈可能となることを示した。また、対話型の意思決定タスクでは、ReActは1回または2回のプロンプトだけで模倣学習や強化学習を上回り、成功率を34%、10%向上させた。さらに、ReActはアクションのみの手法と比較して一貫した優位性を示し、モデルの解釈可能性、信頼性、診断性を向上させた。総括すると、ReActは一般的なタスク解決において推論と行動の組み合わせが効果的であることを示した。
【所感】
考えるだけで手を動かさない人(CoTのみ:机上の空論だけな人、ロジックのみな人)や考えなしに手を動かすだけの人(Actのみ:作業だけが得意な人)は現実解に辿り着けないのは人間も同じな所が興味深い。
REACT: SYNERGIZING REASONING + ACTING

一般的に強化学習において方策
を学習する際に、コンテキスト(過去の行動と観測信号)から行動のマッピング
が暗黙的(人間が認知できない様な特徴空間)で計算量が多い場合は困難になる。たとえば、図1(1c)に示されるエージェントは、複雑な推論が必要なQAタスクの文脈(質問、行動1-3、観測1-3)に対して正しい最終行動(Act 4)を生成することができない。同様に、図1(2a)に示されるエージェントは、文脈からsinkbasin 1にpeppershaker 1が含まれていないことを理解できず、幻覚的な行動を続けてしまう。
ReActにおける提案はシンプルで、エージェントの行動空間に言語空間という新しい軸を追加する。この言語空間は thought もしくは reasoning traceと呼ばれるもので、外部環境に変化をもたらさない代わりにコンテキストを更新する。これはタスクを分割したり、プランを立てたり、プランを修正したり、常識を埋め込んだり、進捗を把握したり、例外を把握したりといった思考を指す。
しかし、言語空間は無限であるため学習は困難であり、事前知識が必要とされる。本論文では、主に大規模言語モデルPaLM-540B(Chowdhery et al.、2022)を使用し、少数のコンテキスト内の例を与えてドメイン固有のアクションと自由形式の思考を生成し、タスクの解決に取り組む(図1(1d)、(2b))。各コンテキスト内の例は、タスクのインスタンスを解決するためのアクション、思考、および環境観測の記録である(付録Cを参照)。推論が主要な役割を果たすタスクの場合(図1(1))、思考とアクションの生成を交互に行い、タスクの複数の思考-行動-環境観測のステップから構成されるようにする。一方、多数のアクションが関与する意思決定タスクの場合(図1(2))、思考は最も関連性の高い空間に疎に生成できれば十分であり、思考とアクションの非同期な連携は言語モデルが決定する。
提案した統合的推論動作(ReAct)の効果:
- 推論・行動の設計が柔軟性が高く容易。few-shotで必要とされた文選択は不要
- 高い汎化性。少ない学習データでも新しいタスクにおいて頑健
- 人間との調和性が高い。意思決定と推論プロセスは解釈可能な形で提示され、推論過程をレビューし編集すること(Human-in-the-Loop)でエージェントの制御が可能
実験
KNOWLEDGE-INTENSIVE REASONING TASKS での評価
多段質問応答や事実検証などknowledge-intensive reasoning を必要とするタスクでの性能評価実験。HotPotQA、FEVERのデータセットを用いた。行動空間は検索エンジンに問い合わせるsearch[entity]、検索結果から必要な情報を探すlookup[string](ブラウザのCtrl+Fに相当)、行動の終了を表すfinish[answer]の3つとした。
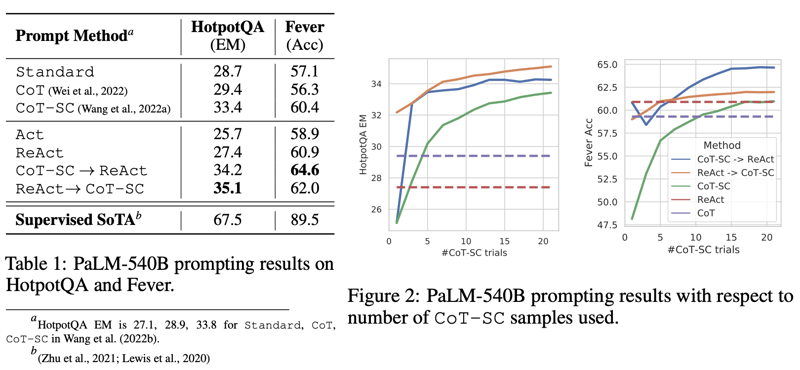
表1と図2の右矢印は途中での ReAct と CoT-SC の切り替えを示す。ReAct → CoT-SC は ReAct が与えられた思考ステップ回数以内に答えに辿り着けなかったらCoT-SCへ切り替えるもので、HotpotQAでは7回、FEVERでは5回に設定した。CoT-SC → ReAct は逆にCoT-SCで過半数を占める回答が存在しなくなった(=内部知識では自信のある回答を導けない時)らReActへ切り替える。
ReActのみはCoTよりも性能が低い場合が多く、これはReActは外部知識ベースを利用してより具体的で信頼性の高いアプローチを持つが、推論の柔軟性はCoTよりも少ないことが原因である。また、ReActでは情報のある知識の検索が重要で、情報がない検索はエラーを増やす原因となる。これらの観察に基づいて、二つの方法を組み合わせる戦略である ReAct + CoT-SC がベストの結果であった。
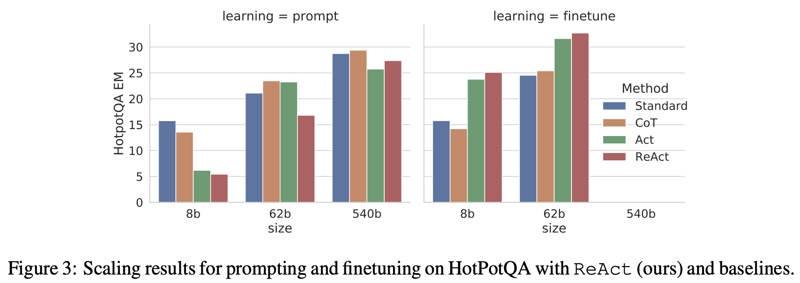
興味深い点として CoT,ReAct ともにモデルサイズの影響を強く受け、さらにfinetuneと組み合わせると異なる結果となるところである。8B程度の小さいLLMではCoTはほぼ効果なし、ReAct は逆効果であり、これは推論と行動を少ない例から知識獲得するのが困難であることが原因と考えられる。しかし、finetuneされたモデルの場合はReActは大幅に改善する。
DECISION MAKING TASKS での評価
インタラクティブな意思決定タスクである、ALFWorldとWebShopで評価した。これらのタスクは複雑な観測環境、スパースな報酬を特徴とし、エージェントが長期的視野で効率的な推論による行動と探索が必要とされる。
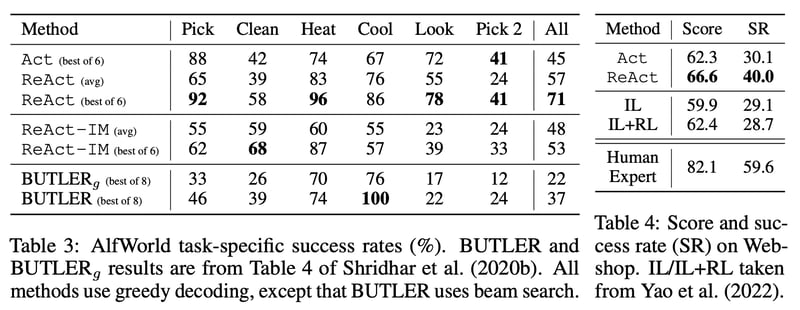
先行研究と比較して、ReActは柔軟で多様な推論を実現し、タスクに応じて異なる推論タイプを使用できる。また、他の方法と比べて優れた性能を示しており、特にIMスタイルの外部フィードバックを使ったReAct-IMよりも大幅に高い成功率を示した。ReActの利点は、高レベルの目標の分解や共通の推論により、環境内でのアクションの理解と効果的な探索が可能であることが観察されている。

補足として図5に Human-in-the-loop の概念を取り入れたReActの例を示した。この例では人間の介入による幻覚の修正、新しい知識の注入を行なうことで正解に辿り着くことができるようになった。このような介入は従来のエージェントの状態空間が認知不可能であった強化学習とは異なり、ReActでは言語という形で介入が可能になっている。


















