複数の異常検出系の手法が実装されている intel 製のライブラリ。
Paper: Anomalib: A Deep Learning Library for Anomaly Detection
Code: https://github.com/openvinotoolkit/anomalib
以下のモデルが実装されている。
- PaDiM(2020): a Patch Distribution Modeling Framework for Anomaly Detection and Localization
- PatchCore(2022): Towards Total Recall in Industrial Anomaly Detection
- CFLOW-AD(2022): Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
- CFA(2022): Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
異常検知にはAuto-Encoder等を用いたReconstruction-basedなアプローチと中間層の情報の類似性から判断するEmbedding similarity-basedなアプローチがありPadimは後者である。
https://arxiv.org/pdf/2011.08785.pdf
概要
社会課題:異常検知はFAや監視システムで活用できるが、異常時のデータを集めるのは困難である。
技術課題:正常時データのみで効率的に学習したい
従来技術:深層学習モデルやkNNに頼ったものが多いが、学習に多くのデータと時間がかかる。
提案:事前学習済みモデルの中間層のモデルパラメータの分布を活用する。
効果: MVTec AD と STC datasetにてSOTAの性能。又、提案手法の時間・空間計算量はデータセットサイズに依存せず、解像度にのみ依存するため従来手法より大幅に削減することができた。
パッチを座標位置ごとにガウス分布でモデル化
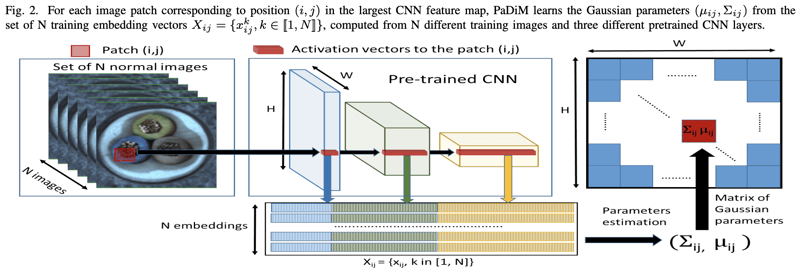
PaDimでは特徴量を画像空間の特定位置のパッチの特徴量分布として定式化を行うが、これをpatch embedding vectorと呼んでいる。patch embedding vector の作成方法は SPADE に似ており、上の図が示すように解像度の異なる複数のレイヤの出力を同一パッチ位置で接合することで作成する。パッチの位置は物体検出モデルYOLOが用いているようなグリッドを導入し、画像をW*Hの格子状に分割して決定する。しかし当然のことながら、patch embedding vectorは多くの冗長な情報を含んでいるため、PCA等の次元削減によって本手法は大幅に計算量を減らすことができる。しかし、実験でも述べるがPCAよりもランダムによる特徴量選択の方が性能が高かった。
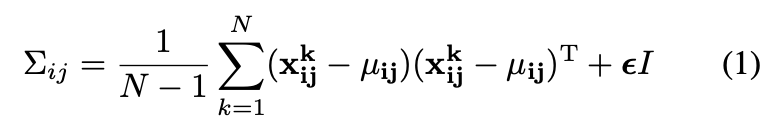
patch embedding vectorは多変量ガウス分布を用いてモデル化・学習がなされ、複数レイヤ間の共起性を捉えることができる。この複数レイヤを接合する効果は(Section V-A)の実験で示されている。
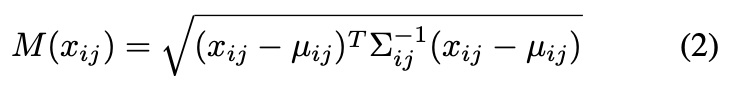
異常度は上記マハラノビス距離で学習された多変量ガウス分布との差分を評価する。距離計算はグリッドごとに行われるため、H*W個の距離値が算出される。
実験
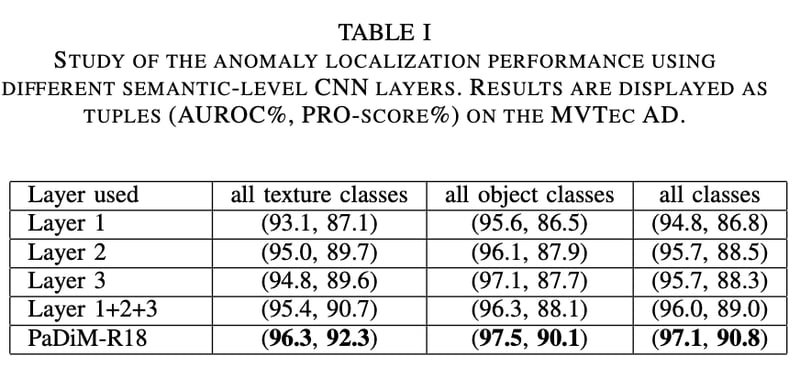
Table1はpatch embedding vectorの相関性を学習した効果を確認するためのablation studyである。Layer1+2+3とアンサンブル化するよりもPadimの混合ガウシアンによって相関性を学習した方が精度が高いことが示されている。
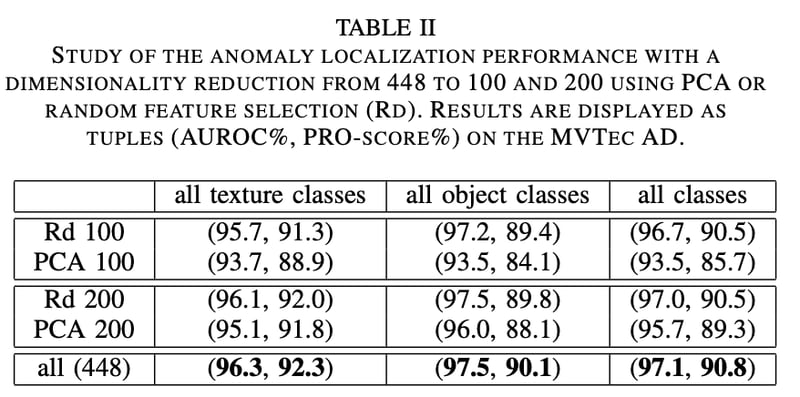
Table2はpatch embedding vectorの次元削減による精度への影響を調査した実験結果である。RD100はランダム選択による次元削減であるが、実はランダム選択の方がPCAによる削減よりも精度低下量が少ない。これはPCAが主成分として選択する次元方向は特徴量の分散が小さい方向なので、主に正常クラスの特徴次元を残してしまうためだと考えられる。
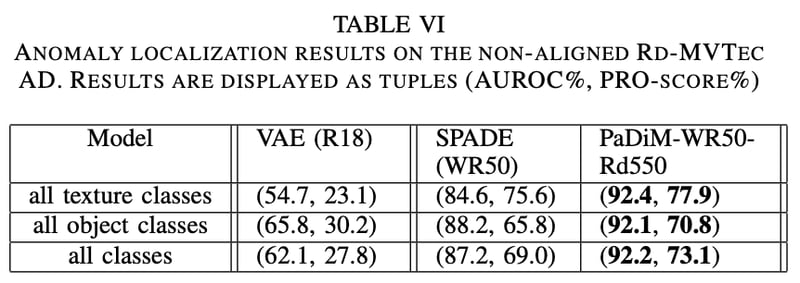
実際のリアルな異常検知アプリケーションの状況に近い評価をするために、MVTec ADを [-10°, 10°]の範囲で回転させたりクロップさせたりして non-alignedなデータセット Rd-MVTec AD を作成した。このデータセットでの実験結果は Table.4 のように提案手法が最も高精度となった。
Towards Total Recall in Industrial Anomaly Detection (PatchCoreの論文)
未調査。。
CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
Normalizing flowベースの異常検出手法。
Paper: https://arxiv.org/pdf/2107.12571.pdf
Code : https://github.com/gudovskiy/CFLOW-ad
Tech Blog: https://zenn.dev/takoroy/articles/cb94378e9ae6a0
社会課題:画像モーダルにおいてリアルタイムな異常検知手法が求められている。
技術課題: 特徴抽出された表現ベクトルが(ガウシアン分布などの)パラメトックなアプローチでモデル化できるとは限らない。
従来技術: 従来のsimilarity-basedアプローチでは(計算量削減のため)よく使われる統計分布でモデル化していることが多く、異常検出を困難にした。
提案: Normalizing flowを用いた定式化により任意の密度関数を推定でき、特徴抽出にしようするEncoderの特性によらない、より自然な異常検出モデルを構築できると考えられる。
効果: MVTec データセットにおいてSOTAの性能となった。又処理速度に関しても既存手法より非常に高速に動作できることを確認した。
CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
Paper: https://arxiv.org/pdf/2206.04325.pdf
Code: https://github.com/sungwool/CFA_for_anomaly_localization
【社会課題】
異常検知はFAや監視システムで活用できるが、異常時のデータを集めるのは困難である。
【技術課題】
異常検知では学習とテストセットのノーマルクラスの分布は多くの場合異なるという、いわゆる OOD(Out of Distribution) 条件である。この場合はデータセットバイアスにより正しく認識できなくなる。
【従来技術】
ターゲットドメインへのドメイン適応は行なってこなかった。
【提案】
ソースドメインで学習したモデルパラメータを効率的にターゲットドメインに転移学習する方法を提案。
【効果】
MVTec ADで99.5 AUROCを達成した
Coupled-hypersphere-based Feature Adaptation
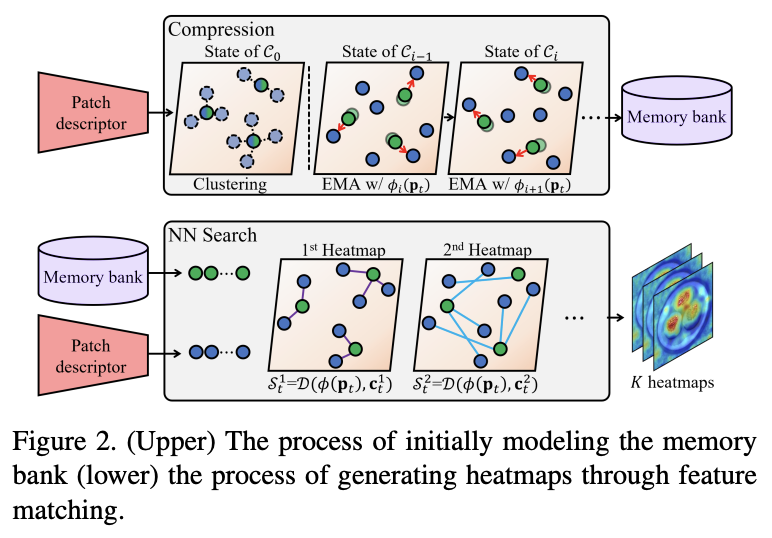

PaDim, PatchCore に比べて特徴的なのはメモリバンクの圧縮である(図2)。トレーニングセットの最初の正常サンプルから特徴を抽出し、K-meansクラスタリングを使用して初期メモリバンクC0を作成。次に、各正常サンプルに対して、前のメモリバンクから最も近いパッチ特徴のセットを検索し、指数加重移動平均(EMA)を使って次の状態のメモリバンクCiを計算する。これを正常サンプル全体に対して繰り返すことで、最終的なメモリバンクCにはトレーニングセットを代表する正常な特徴が格納されるようになる。実際に他手法と比べると空間計算量は小さく、データセットサイズに依存しない。


















