選定理由
Forensic Timeline というニッチ分野におけるIEEE論文。ドメインはセキュリティ系。
Paper: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9047947
Code: N/A
以前調査した[Silalahi2023]でも引用されている
概要
【社会課題】
セキュリティインシデント後のデータ分析で、重要なイベントやアクティビティを効率的に特定することは、フォレンジック調査者にとって時間とコストのかかる作業である。
【技術課題】
ログファイルから取得したイベントを効率的に識別・解析する方法が不足している。特に、どのログメッセージが実際に調査の関心を持つイベントを示しているのかを判断することが難しい。
【提案】
ログメッセージから興味のあるイベントを自動的に抽出するために、コンテキストとコンテンツのアテンションモデルを組み合わせて、ログ内のアスペクトタームとその感情値を識別する深層学習技術を提案した。
【効果】
初期テストでは、F1スコアで98.43%、精度で99.64%の高いパフォーマンスが達成された。本技術によってフォレンジック調査の大幅なコスト削減が見込まれる。
Context and content attention model for forensic timeline
Overview
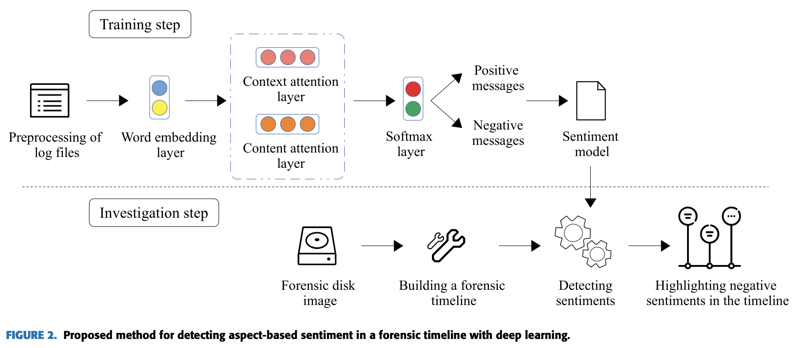
全体像を図2に示す。学習ステップは前処理によって正例と負例を含むサンプルを抽出後に、単語埋め込みが行われ、モデルの学習へ使用される。推論ステップではフォレンジック対象のディスクからまず全体のタイムラインが構築され、これに対して学習済みモデルを使用してハイライトすべきイベントが抽出される。
Preprocessing

ログメッセージの感情値を取得するために、各ログエントリーは別々のエンティティに分割する。ログエントリーによく見られるエンティティには、タイムスタンプ、ホスト名、プロセス名、特定のイベントに関する短い説明がある。図3はログエントリのエンティティ解析プロセスの例である。
解析にはnerlogparserツールを使用した。これは、双方向の長期短期記憶という事前学習済みの深層学習モデルを使用して、ログエントリ内の各エンティティを自動的に分割することができる。nerlogparserの出力は、ログファイル内のすべてのレコードのエンティティ名と値を含むJSONファイル、または辞書データ構造で出力される。
Word Embedding
単語埋め込みはGloveを使用した。長いログは切り詰め、短いログはパディングを実施して、長さを揃えた。
Model
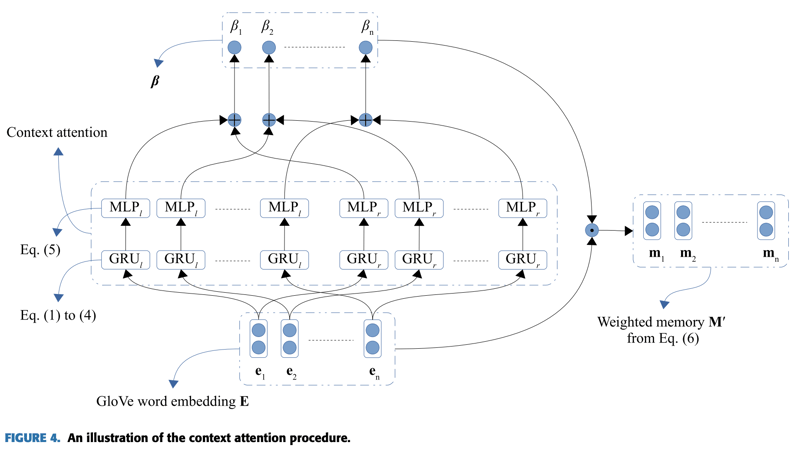
context attentionは図4に示すアーキテクチャである。
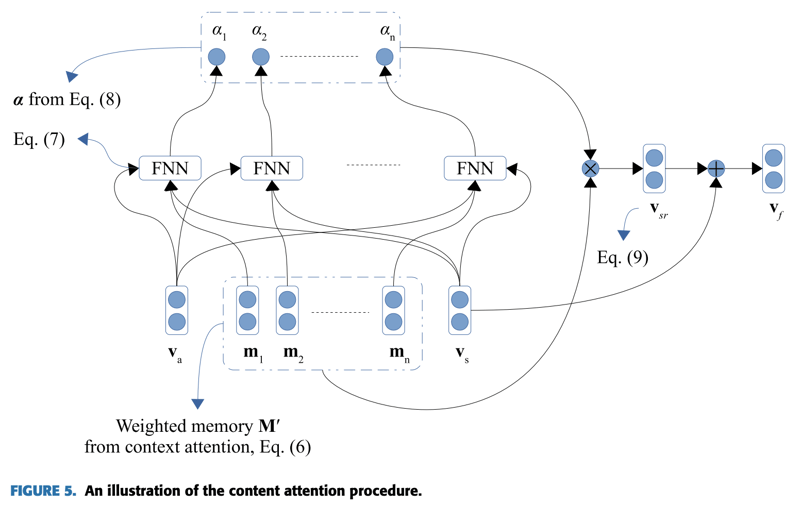
content attentionは図5に示すアーキテクチャである。
最終的にsoftmax層を通じてポジティブ、ネガティブに対する分布を得る。
Build Timeline
最初のタイムライン構築にはplaso(旧log2timeline)を用いる。検出されたタイムスタンプを用いて時系列でソートされたcsvファイルを得る。
plasoツールによって生成されるCSVファイルには、日付、時刻、ソース、タイプ、説明など、17の事前定義された固定フィールドが含まれる。感情分析では、システムからの特定のイベントの主要なメッセージと説明を含む「説明」フィールドをモデルへのインプットとする。法医学的なタイムラインを構築する際、ログエントリを解析するためにnerlogparserツールは使用しない。タイムラインの視覚化には、Timesketchを使用する。
Experiment
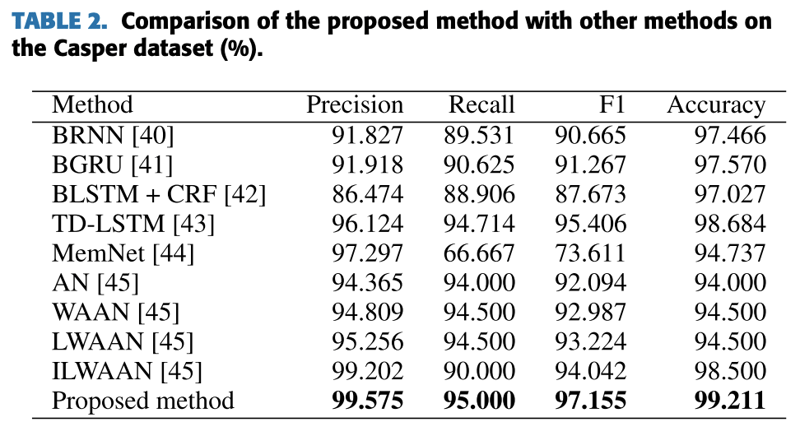
Casperオープンデータセットでの比較が表2である。従来手法と比べてもSOTAである。
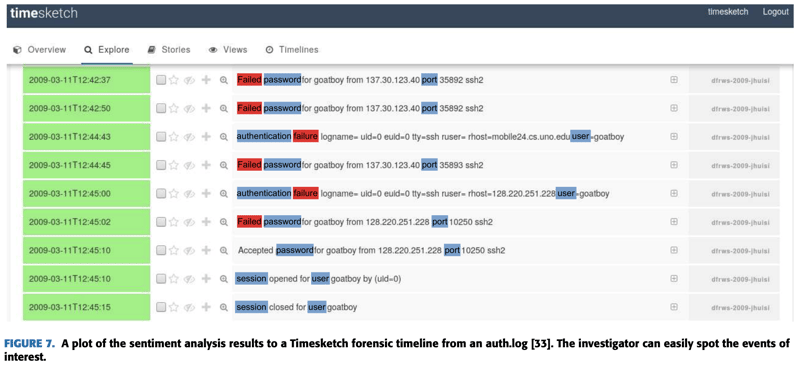
Timesketchでの表示結果は図7である。青色はアスペクトワードを、赤色はその感情を示している。DFRWS 2009のケースでは、ユーザーが違法なファイル(このケースでは薬のレシピ)を転送した疑いが持たれている。「goatboy」というユーザーがMardi Grasの画像とビデオライブラリのサブスクリプションと引き換えにこの違法な薬のレシピファイルを持っている。


















