選定理由
LLMを活用した情報検索(Generative Information Retrieval/Retrieval-Enhanced LLM)のトレンドに乗った研究、SIGIR-AP採択。
Paper:https://arxiv.org/abs/2309.11392
Code: N/A
概要
【社会課題】
大規模言語モデルは誤情報や誤解を招く情報を説得力ある形で回答すること(hallucination)があり信頼性に問題がある。
【技術課題】
生成された回答が本当かどうか、外部ソースと照合するために関連する情報を検索し、判定しなければならない(=RAGの課題)。又、回答に複数の事実列挙が入り混じる場合はそれの根拠となる文書も多岐に渡るため検索でヒットしにくくなってしまう。
【検証】
LLMの回答を文書集合と自動的に照合する方法を提案。大規模データベース(MS MARCO V1)から証拠を検索するためのRAGパイプラインと、その証拠文書に対して自身で生成した回答を自己検証するプロセスで構成される。又、事実ごとに分解して検証する方法も提案し、効果を分析した。
【結果】
hallcination を80%以上の精度で自己検出することができたが、完璧ではなかった。依然として特に生成結果がユーザーに直接提示されるような場合やミッションクリティカルなタスクでは注意が必要である。
検証1(hallucinationの自己検出)
検証内容
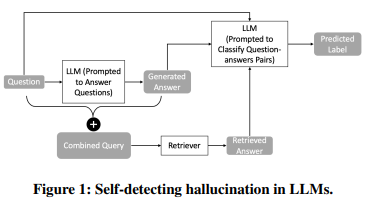
第一の検証は同じLLMで hallucination を自己検出できるかを目的とした。
図1に示すように、質問文とその回答を接合したクエリを用いて検索し、検索結果と回答を自己検証時の質問文として用いた。LLMとして温度パラメータを0に設定したgpt-3.5-turboを使用した。入力データセットとして、800万以上のパッセージを含むMS MARCO(V1)を使用し、6980の質問に関する実験を行った。

Retriever では3つの検索方法を用いた。
1.パラメータをMS MARCOに最適化したOkapi BM25ランキング関数による検索。
2.パッセージの質を評価するニューラルネットワークベースの検索方法。疎な検索(SPLADE)と密な検索(ANCE)のアンサンブルを行う初期検索により上位100のドキュメントを回収し、そのあとMonoT5とDuoT5のニューラルリランカーを用いたリランキングを行う。先行研究ではこの検索方法はMS MARCOスモールセットでMRR@10で0.40となっており、Pyseriniに実装されている。
3.上記の手法の上位3つのパッセージを接合し、LLMで要約したものを検索結果とする。使用したプロンプトは図6である。
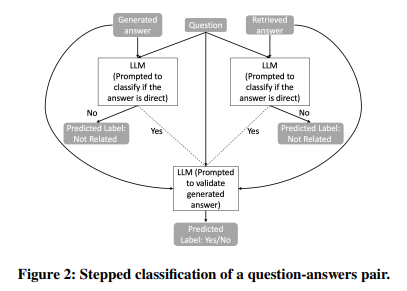


図1における generated answer と retrieved answer を照合するために、LLMによる段階的な分類プロセスを採用した(図2)。まず、図4のプロンプトを用いてLLMが両方のanswer を評価し、両方が質問に対する直接的な回答であると分類された場合のみ、図5のプロンプトを用いてgenerated answerが retrieved answer に支持されているかどうかを判断する。LLMの判断は「はい」「いいえ」「関連性なし」の3つのクラスに分類され、これらはそれぞれhallucinationなし、hallucination の可能性あり、元の質問に対して回答できていないことを示す。また、人間のアノテーターが関連性が高いと評価したパッセージについても実験し、アプローチの有効性検証に使用した。
検証結果
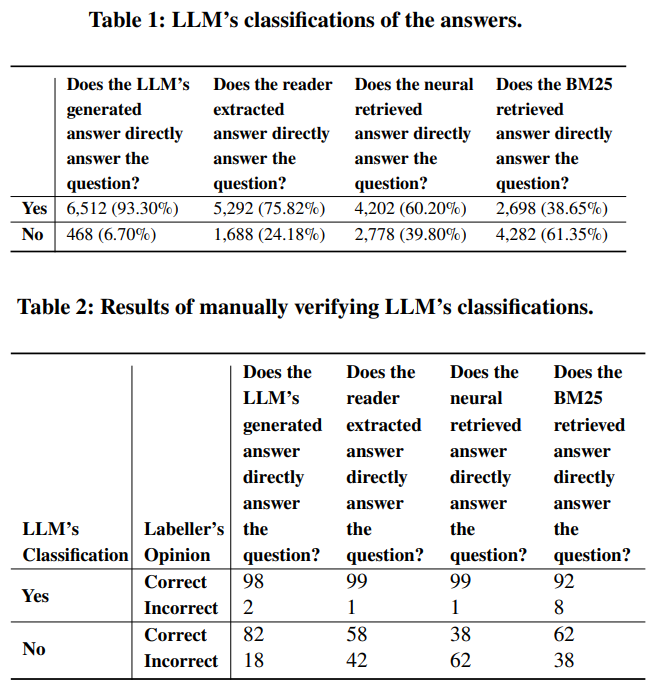
LLMの分類結果は表1である。検索性能ではLLMによる要約、ニューラルネットワークベース、BM25の順で性能が良かった。又、表2からはLLMによる分類は false negatives の方がfalse positivesより多いことがわかる。
検証2(事実ごとの分析効果検証)
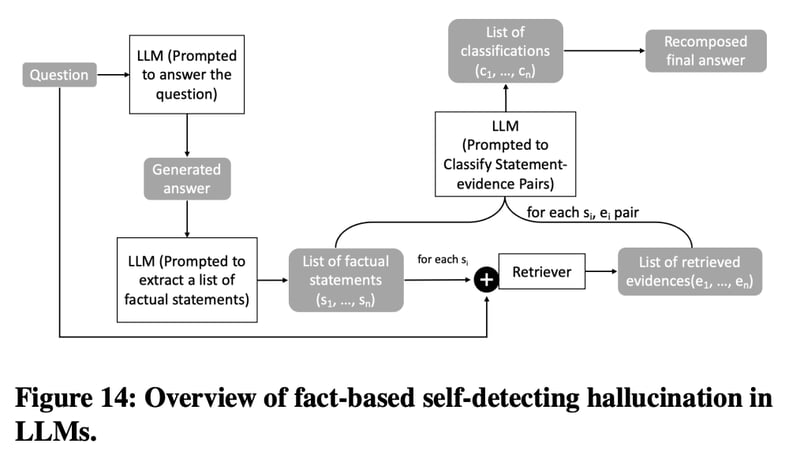
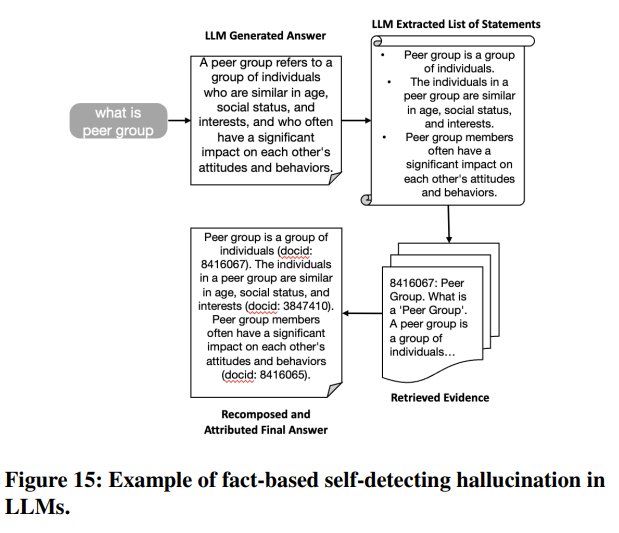
第二の検証は複数の事実を含む場合は事実ごとに判定が必要であるため、回答を事実ごとに分解することの効果分析を目的とした。このような事実記述(factual statement)の分解は FActScore や RARR にも同様の概念がある。検証のためのパイプラインは図14のようにgenerated answerを直接評価する前に分解するプロセスを導入する。図15は1つのサンプルがパイプラインで処理される例である。

図16は事実記述を分解するためのプロンプトである。

図17は事実検証をするプロンプトであり、Supported:hallucinationなし、Contradictory:hallucinationあり、Neither:回答が無関係、の3クラスに分類する。

図18は判定がContradictoryだった場合にhallucinationを除去する修正をするためのプロンプトである。
検証結果
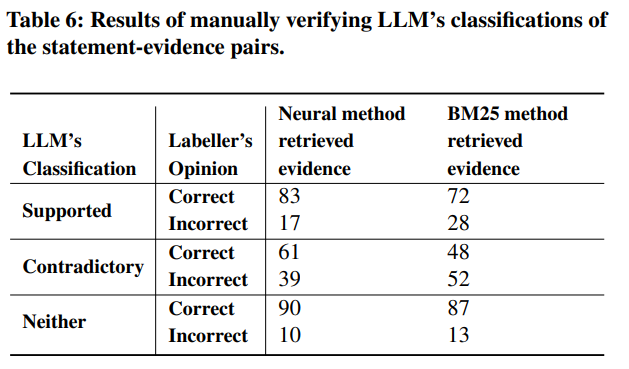
6980のサンプルのうち61は事実を何も抽出できなかった。事実の分解はおおむね問題なくできているが、記述を冗長にしてしまう場合があった。LLMが生成した事実主張の約85%が取得したサンプルによって。各クエリにおいて支持される主張の平均は約80%で、生成された回答の約70%については自動パイプラインによる幻覚はなかった。また、ニューラルリトリーバーを用いた証拠文書の検索の方がBM25よりも若干優れていた。


















