選定理由
知名度高い。強化学習ともつながりが深い。
Paper: https://arxiv.org/abs/2305.10601
Code: https://github.com/kyegomez/tree-of-thoughts
blog: https://qiita.com/PND/items/56c5e30d5a568188eb1c
概要
【社会課題・技術課題】
現状の言語モデルは現時点で観測されるトークンレベルでの left-to-right な意思決定プロセスに制約されている。これにより、局所的探索、戦略的先読み、または初期段階での決定が重要なタスクでモデルが十分に機能しない可能性がある。
【提案】
CoTを一般化した Tree of Thought を提案。ToTは、テキストの一貫した1つの思考単位("thoughts")に対する探索を可能にし、この中間状態を経由して問題解決を目指す。ToT により、言語モデルは複数の異なる論理的経路を考慮し、次の行動を(強化学習のように)自己評価することで多段論理ステップが必要な課題解決や意思決定を行えるようになる。また、よりグローバル最適解を得るために木構造上の先読みやバックトラックを行うことができる。
【効果】
実験結果では、ToTは三つの新しいタスク(Game of 24、Creative Writing、Mini Crosswords)といった初期段階での計画性や検索が必要なタスクにおいて、言語モデルの問題解決能力を大幅に向上させている。例えば、Game of 24では、Chain of ThoughtプロンプティングのGPT-4が4%しか解決できなかったのに対し、ToTを使用することで74%の成功率を達成した。
Tree of Thought
着眼点
人間の問題解決における行動を分析した研究[Newell1959]によれば、人は(無意識に)ノードが部分的な解、エッジはそれを修正する演算子を表す木構造を用いて問題解決していると考えられる。この探索空間を航行し解となるノードに辿り着くまで知見とヒューリスティックな判断によって進むノード決定する。このアナロジーからヒントを得ると、既存の現状の言語モデルを使用して一般的な問題を解決する際の欠点は、局所最適解の探索においては異なる経路パス(=少し離れた探索空間)を十分に探索できず、大域最適解の探索においてはプランニング、先読み、バックトラッキングなどのヒューリスティックに基づく探索が組み込まれていないことである。
提案
そこで、思考ステップを分解し、潜在的な思考の生成をしながら、ノードの各状態の発見的評価方法と木構造を探索するアルゴリズムを導入することで人間の問題解決の思考法を模倣した ToT(Tree-of-Thought) を提案する。
明確な分解なしに同一の状態から思考を行う CoT と違って、ToT は問題の特性を考慮し思考のステップを分解するが、思考の粒度は言語モデルがノード間を識別可能で多様なサンプルを生成できるほど小さく、又、言語モデルが問題解決に向けた見通しを評価できる程度には大きい必要がある。これは、問題によって、数語~一段落の文章まで多様な大きさになり得る。
思考ジェネレータがとる戦略としてsample戦略とpropose戦略がある。sample戦略ではCoTプロンプトを用いて i.i.d思考を生成する。この戦略は探索空間が膨大であるタスクに適しており、例えば文章の生成などである。
![]()
もう1つのpropose戦略では多様性を持つ思考を生成させる独自のプロンプトによって生成させる。この戦略を用いるべきタスクとしては探索空間が限定的である場合(制約充足問題)であり、例えばパズル等である。
![]()
状態エバリュエータはどの状態を優先的に探索するべきであるか評価するもので、従来ルールベースなアプローチ(DeepBlue)や学習ベースなアプローチ(AlphaGO)がある。我々はさらに柔軟性の高いアプローチとして事前学習済み言語モデルベースの状態エバリュエータを用い、value戦略とvote戦略の2つを提案した。value戦略は他のノードの状態とは無関係に単一でノードの状態を独自のプロンプトで実数値[0, 10]や分類(sure/likely/impossible)で評価する。この際に先読みや常識推論といった概念も活用できる。この評価値は完全なものである必要はなく、近似値である。vote戦略はノードの状態1つだけでは評価が難しい場合に独自のプロンプトを用いて多数決を行うもので、CoT-SCに近い。

木構造を探索するアルゴリズムとして本研究では最も基本的なBFS, DFSを利用した。A*やMCTSなど高度なアルゴリズムは今後の研究課題である。
実験

3つのタスクで実験しているがcreating writingに絞って説明する。これは4つのランダム文を入力としてその各文で終わる4つのパラグラフを一貫性があるようなストーリーで記述するタスクであり、高度な計画性を必要とする。
ランダム生成文として randomwordgenerator.com を用いて100個の文を作成した。文章の一貫性の評価には、GPT-4を使用して1-10のスコアを割り当てる方法と、人間による定性評価を用いた。前者の方法では、出力ごとに5つのスコアを平均したものを用い、標準偏差は0.56であった。

木構造の深さは2、分岐数は5に設定した。最初の分岐で5のプランを出力し、次の分岐で5のパッセージ列を出力した。vote戦略で選択されるのは1つのみで、
vote promptとして “analyze choices below, then conclude which is most promising for the instruction” という文章を使用した。又、言語モデルに完全に一貫性があるかどうかを判定させて洗練する iterative-refine を後処理として追加した。
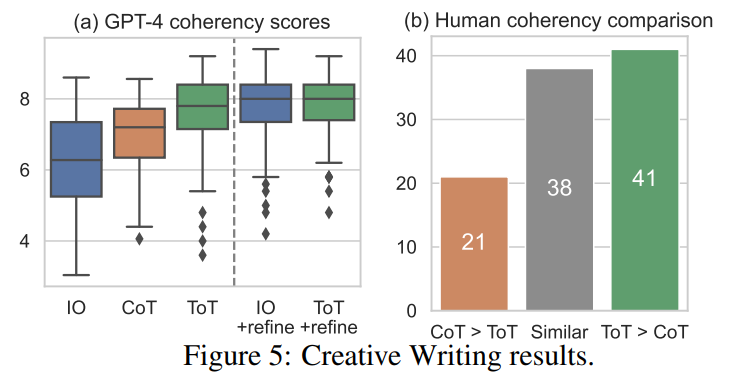
ToTは100の文章作成にてGPT-4で平均7.56を獲得し、IO(6.19)やCoT(6.93)よりも一貫性のある文章を生成する評価結果となった。人間の判断でも、ToTがCoTより好まれることが41回、逆にCoTがToTより好まれることが21回あり、残りの38ペアは同様に一貫性があるという結果になった。さらに、 iterative-refine は文章生成タスクには効果的で、IOとToTの一貫性のスコアをそれぞれ7.67、7.91に向上させた。


















