This is a Plain English Papers summary of a research paper called Arctic-Embed: Scalable, Efficient, and Accurate Text Embedding Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper presents Arctic-Embed, a new approach to building efficient and accurate text embedding models that can scale to large datasets.
- The key contributions include a novel model architecture, training strategy, and techniques for reducing the memory and compute requirements of text embedding models.
- The authors demonstrate the effectiveness of Arctic-Embed on a range of tasks, showing that it outperforms existing state-of-the-art models in terms of accuracy, efficiency, and scalability.
Plain English Explanation
Text embedding models are a fundamental component of many natural language processing (NLP) systems, as they allow text data to be represented in a numerical format that can be used by machine learning algorithms. However, building high-quality text embedding models can be challenging, as they need to balance accuracy, efficiency, and the ability to scale to large datasets.
The Arctic-Embed paper introduces a new approach to addressing these challenges. The key idea is to use a novel model architecture and training strategy that can produce accurate text embeddings while requiring less memory and computation than existing methods.
At a high level, the Arctic-Embed model works by first learning a set of "anchor" embeddings that capture the core semantics of the text data. It then uses a special encoding layer to generate the final text embeddings by combining the anchor embeddings with additional context-specific information. This approach allows the model to achieve high accuracy without needing to store or compute a large number of parameters.
The authors also introduce several techniques for further improving the efficiency and scalability of Arctic-Embed, such as using efficient attention mechanisms and techniques for reducing the memory footprint of the model. They demonstrate the effectiveness of their approach on a range of NLP tasks, showing that Arctic-Embed outperforms existing state-of-the-art text embedding models in terms of accuracy, efficiency, and the ability to scale to large datasets.
Overall, the Arctic-Embed paper represents an important advance in the field of text embedding models, providing a new approach that can help make these models more practical and useful for a wide range of real-world applications.
Technical Explanation
The Arctic-Embed paper introduces a novel text embedding model that is designed to be more efficient, scalable, and accurate than existing approaches.
At the heart of the Arctic-Embed model is a unique architecture that combines a set of "anchor" embeddings with a specialized encoding layer. The anchor embeddings are learned in an unsupervised way to capture the core semantics of the text data, while the encoding layer is used to generate the final text embeddings by combining the anchor embeddings with additional context-specific information.
This approach allows Arctic-Embed to achieve high accuracy without needing to store or compute a large number of parameters, as is the case with many existing text embedding models. The authors also introduce several techniques for further improving the efficiency and scalability of their approach, such as using efficient attention mechanisms and techniques for reducing the memory footprint of the model.
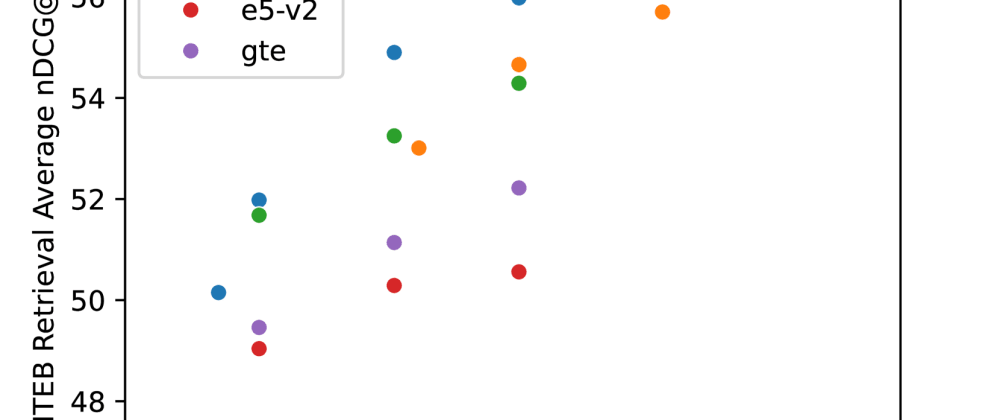
To evaluate the performance of Arctic-Embed, the authors conducted experiments on a range of NLP tasks, including text classification, sentence retrieval, and knowledge base completion. Their results show that Arctic-Embed outperforms existing state-of-the-art text embedding models in terms of accuracy, efficiency, and the ability to scale to large datasets.
Critical Analysis
The Arctic-Embed paper presents a compelling approach to building efficient and scalable text embedding models. The authors' use of anchor embeddings and a specialized encoding layer is a clever way to achieve high accuracy while reducing the memory and compute requirements of the model.
However, the paper does not address a few potential limitations of the Arctic-Embed approach. First, the reliance on anchor embeddings means that the model's performance may be sensitive to the quality of the initial unsupervised learning step. If the anchor embeddings do not capture the right semantic information, the overall model performance could suffer.
Additionally, the paper does not provide much insight into the interpretability of the Arctic-Embed embeddings. While the model may be more efficient and accurate than existing approaches, it's unclear whether the embeddings produced by the model are as easily interpretable or explainable as those generated by other methods.
Finally, the paper focuses primarily on the evaluation of Arctic-Embed on traditional NLP tasks, such as text classification and sentence retrieval. It would be interesting to see how the model performs on more complex or domain-specific tasks, or how it could be used in real-world applications beyond just academic benchmarks.
Overall, the Arctic-Embed paper represents an important contribution to the field of text embedding models, but future research could further explore the limitations and potential applications of this approach.
Conclusion
The Arctic-Embed paper introduces a novel text embedding model that is designed to be more efficient, scalable, and accurate than existing approaches. By using a unique architecture that combines anchor embeddings with a specialized encoding layer, the authors are able to achieve high performance without the need for large, memory-intensive models.
The key contributions of the Arctic-Embed paper include the novel model architecture, the techniques for improving efficiency and scalability, and the strong experimental results demonstrating the model's effectiveness on a range of NLP tasks. This work represents an important step forward in the development of high-quality text embedding models that can be deployed in real-world applications.
While the paper does not address all of the potential limitations of the Arctic-Embed approach, it lays the groundwork for further research and development in this area. As the need for efficient and scalable text processing continues to grow, the ideas and techniques presented in this paper will likely become increasingly important for a wide range of NLP applications.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.


















