This is a Plain English Papers summary of a research paper called Observational Scaling Laws and the Predictability of Language Model Performance. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper investigates observational scaling laws and their ability to predict the performance of language models.
- The authors analyze how the performance of language models scales with factors like model size, dataset size, and compute power.
- They find that observational scaling laws can accurately predict language model performance, even for large models and datasets.
- The insights from this research could help guide the development of future language models and other AI systems.
Plain English Explanation
The paper looks at how the performance of language models, which are AI systems that can generate human-like text, changes as key factors like the model size, dataset size, and compute power are increased. The researchers found that they could use mathematical "scaling laws" to accurately predict how the model's performance would improve as these factors were scaled up.
For example, they discovered that as you double the number of parameters (the internal settings) in a language model, its performance on certain tasks tends to increase by a predictable amount. Similarly, they found patterns in how performance scales with the size of the training dataset or the amount of computing power used.
These insights are valuable because they can help guide the development of future language models and other AI systems. Rather than having to train and test many different model configurations, researchers can now use the scaling laws to estimate how a model's performance will change as it is scaled up. This could lead to faster and more efficient AI development.
The key takeaway is that there appear to be fundamental "laws" governing how the performance of language models scales, and these laws can be leveraged to make accurate predictions about the capabilities of even very large and powerful AI systems.
Technical Explanation
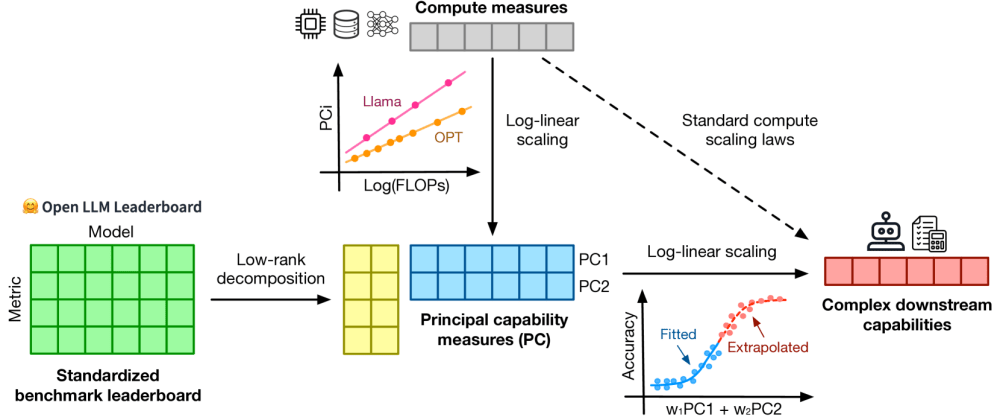
The paper investigates observational scaling laws and their ability to forecast the performance of large language models. Observational scaling laws describe how model performance scales with factors like model size, dataset size, and compute used during training.
The authors perform an empirical analysis across 16 language models, ranging from small to state-of-the-art models like GPT-3. They measure performance on a variety of natural language processing tasks and find that simple scaling laws can accurately predict model performance, even for massive models and datasets.
Specifically, the authors find that log-linear scaling laws, where performance grows logarithmically with factors like model size and dataset size, provide good fits to the observed data. This suggests there may be underlying dynamical principles governing the scaling of language model performance.
The insights from this research could help guide the development of future language models and other AI systems. By understanding how performance scales, researchers may be able to more efficiently explore the capabilities of large-scale models and make better predictions about their behavior.
Critical Analysis
The paper provides a comprehensive empirical analysis of scaling laws for language models, but there are a few potential limitations and areas for further research:
The study focuses on a relatively narrow set of language modeling tasks. It would be valuable to assess whether the observed scaling laws generalize to a broader range of natural language processing applications, including more open-ended generation tasks.
The paper does not delve deeply into the causal mechanisms underlying the observed scaling laws. Further research is needed to understand the fundamental principles driving these patterns.
The analysis is limited to text-based language models. It remains to be seen whether similar scaling laws apply to speech-based language models or other types of generative AI systems.
Overall, this paper makes an important contribution by rigorously demonstrating the predictive power of observational scaling laws for language models. However, there are still open questions about the generalizability and underlying causes of these scaling phenomena that warrant further investigation.
Conclusion
This paper presents a comprehensive analysis of observational scaling laws and their ability to forecast the performance of large language models. The authors find that simple log-linear scaling laws can accurately predict model performance across a range of natural language processing tasks, even for massive models and datasets.
These insights could have significant implications for the development of future language models and other AI systems. By understanding how performance scales with factors like model size and dataset size, researchers may be able to more efficiently explore the capabilities of large-scale models and make better predictions about their behavior.
While the paper focuses on text-based language models, the principles of observational scaling laws may extend to other generative AI applications as well. Further research is needed to fully understand the causal mechanisms underlying these scaling phenomena and to assess their broader applicability across the field of artificial intelligence.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.

















