This is a Plain English Papers summary of a research paper called Linearizing Large Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper explores techniques for linearizing large language models, which can significantly reduce the computational cost of inference.
- The authors investigate the application of linear attention mechanisms, tensor decomposition, and other approaches to improve the efficiency of transformer-based models.
- The paper presents experimental results demonstrating the effectiveness of these techniques in reducing model size and inference time, while maintaining competitive performance on various language tasks.
Plain English Explanation
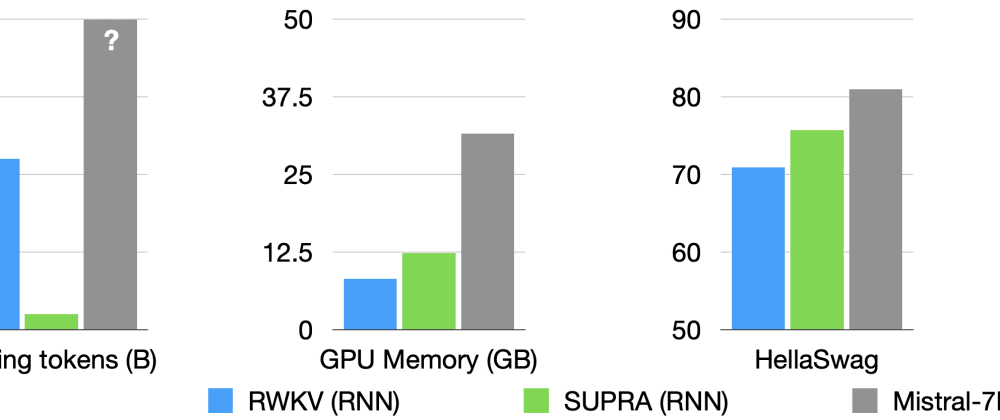
The paper discusses ways to make large language models, like those used in chatbots and text generation, more efficient and faster to use. These models can be very computationally intensive, requiring a lot of processing power and time to generate responses.
The researchers explore different techniques to "linearize" these models, which means finding ways to simplify the complex mathematical operations they perform. This could involve things like using a more efficient attention mechanism or decomposing the model's parameters into more compact representations.
By making these models more linear and efficient, the authors show they can significantly reduce the amount of computing power and time needed to run the models, while still maintaining good performance on language tasks. This could make it more practical to deploy these powerful AI models in real-world applications, like faster response times for chatbots or more efficient training of language models.
Technical Explanation
The paper explores several techniques to linearize large language models and improve their computational efficiency:
Linear Attention: The authors investigate the use of linear attention mechanisms, which can approximate the standard attention used in transformer models at a lower computational cost. This builds on prior work on linear-cost attention.
Tensor Decomposition: The researchers also explore tensor decomposition methods, such as tensor trains, to compactly represent the model parameters and reduce the overall model size.
Other Approaches: In addition, the paper examines other techniques like efficient large language model architectures and accelerated inference for long sequences.
The authors conduct extensive experiments to evaluate the effectiveness of these linearization techniques. They measure the impact on model size, inference time, and performance on various language tasks, demonstrating significant improvements in efficiency while maintaining competitive task-specific results.
Critical Analysis
The paper provides a comprehensive exploration of different approaches to linearizing large language models, which is an important area of research given the computational demands of these models. The authors thoroughly evaluate the techniques and present compelling experimental results.
However, the paper does not address some potential limitations or areas for further investigation. For example, it would be interesting to understand how well these linearization methods generalize to a broader range of language models and tasks, beyond the specific architectures and benchmarks used in the study.
Additionally, the paper does not delve into the potential trade-offs or side effects of these linearization techniques, such as any impact on model robustness, generalization, or interpretability. These are important considerations that could be explored in future research.
Overall, the paper makes a valuable contribution to the field of efficient large language model design, but there are opportunities for further research to address the limitations and explore the broader implications of these linearization approaches.
Conclusion
This paper presents several innovative techniques for linearizing large language models, which can significantly reduce the computational cost of inference without sacrificing model performance. The authors' work demonstrates the potential for improving the practical deployment of powerful language AI systems, enabling faster response times, more efficient training, and broader accessibility.
The findings in this paper are an important step forward in the ongoing effort to make large language models more efficient and scalable, paving the way for their wider adoption in real-world applications. As the field continues to evolve, further research on the trade-offs and broader implications of these linearization methods will be crucial to realize the full potential of these transformative AI technologies.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.


















