This is a Plain English Papers summary of a research paper called CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- A new technique called CoLoR-Filter is introduced for targeted language model pre-training.
- CoLoR-Filter aims to selectively filter training data to focus on specific tasks or domains.
- The method relies on conditional loss reduction to identify the most informative training examples for a given objective.
Plain English Explanation
In the field of natural language processing, training large language models like GPT-3 requires massive amounts of text data. However, this data is often broad and general, which can make it challenging to fine-tune the models for specific tasks or domains.
The researchers behind CoLoR-Filter have developed a new technique to address this issue. Their approach, called "Conditional Loss Reduction Filtering" (CoLoR-Filter), allows for targeted pre-training of language models.
The key idea is to selectively filter the training data, focusing on the examples that are most informative for a particular objective. This is done by analyzing the conditional loss - the amount of error that a model makes on a given training example. By identifying the examples that contribute the most to reducing this loss, the researchers can create a more focused and effective pre-training dataset.
This targeted approach contrasts with traditional data selection methods, which often rely on heuristics or manually curated datasets. CoLoR-Filter's automatic and principled approach can help language models learn more efficiently and perform better on specific tasks, without the need for extensive human curation.
Technical Explanation
The CoLoR-Filter method builds on the idea of using large language models to guide document selection for targeted fine-tuning. However, instead of relying on the model's predictions alone, CoLoR-Filter leverages the model's conditional learning objective to identify the most informative training examples.
Specifically, the researchers propose to compute the conditional loss reduction - the decrease in a model's loss function when a particular training example is added. By ranking the training examples based on their conditional loss reduction, the researchers can then select the most informative subset for pre-training the language model.
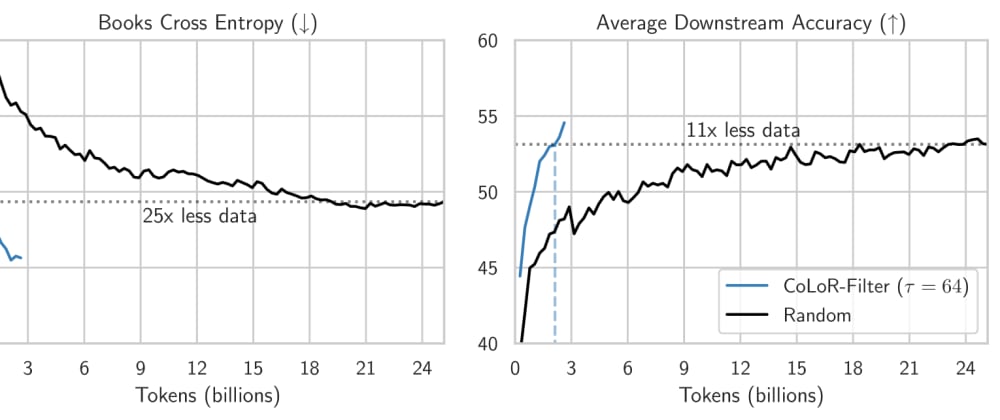
The authors demonstrate the effectiveness of CoLoR-Filter through extensive experiments, comparing it to alternative data selection methods. Their results show that the targeted pre-training approach enabled by CoLoR-Filter can lead to significant performance gains on a variety of downstream tasks, while using a smaller and more efficient training dataset.
Critical Analysis
The CoLoR-Filter paper presents a novel and principled approach to data selection for language model pre-training. By leveraging the conditional learning objective, the method can identify the most informative training examples in an automatic and data-driven manner, reducing the need for manual curation.
However, the paper does not discuss some potential limitations of the approach. For instance, the conditional loss reduction metric may be susceptible to biases in the training data or model architecture. Additionally, the computational overhead of computing the conditional loss for each training example could be a bottleneck, especially for very large datasets.
Furthermore, the paper could have explored the robustness of CoLoR-Filter to different types of downstream tasks and datasets. It would be interesting to see how the method performs on a wider range of applications, including more specialized or domain-specific tasks.
Conclusion
The CoLoR-Filter technique introduced in this paper represents a significant advancement in the field of targeted language model pre-training. By prioritizing the most informative training examples, the method can lead to more efficient and effective model development, with potential benefits across a wide range of natural language processing applications.
While the paper does not address all potential limitations, the core ideas behind CoLoR-Filter are compelling and open up new avenues for further research in data selection and conditional learning. As the field of large language models continues to evolve, techniques like CoLoR-Filter will likely play an increasingly important role in ensuring that these powerful models are optimized for specific tasks and domains.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.


















