This is a Plain English Papers summary of a research paper called VILA: On Pre-training for Visual Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper introduces VILA, a framework for pre-training visual language models.
- VILA aims to improve the performance of vision-language models by incorporating more diverse training data and more comprehensive pre-training tasks.
- The paper explores different training strategies and model architectures for effectively combining visual and language information.
Plain English Explanation
The researchers behind this paper have developed a new approach called VILA (Visual-Language Pre-training) to help improve the performance of models that work with both images and text. These types of "vision-language" models are used for tasks like image captioning, visual question answering, and multimodal understanding.
The key idea is that by doing more comprehensive pre-training - that is, training the model on a wider variety of data and tasks before applying it to a specific application - the model can learn richer representations that allow it to perform better on downstream tasks. The VILA framework explores different ways to structure the model architecture and the pre-training process to most effectively combine the visual and language information.
For example, the model might be pre-trained on a large dataset of images paired with captions, as well as other tasks like predicting which words are relevant to an image. By learning these kinds of multimodal associations during pre-training, the model can then apply that knowledge more effectively when faced with new image-text problems.
The paper experiments with different model designs and pre-training setups to understand what works best for boosting the performance of vision-language models. The goal is to help advance the state-of-the-art in this important area of artificial intelligence research.
Technical Explanation
The VILA framework explores different model architectures and training strategies for effectively combining visual and language information during pre-training of vision-language models.
Previous work has shown the benefits of pre-training vision-language models on large-scale datasets and diverse tasks. VILA builds on this by investigating more comprehensive pre-training approaches.
The paper evaluates different model designs, including:
- Multi-stream architectures that process visual and language inputs separately before combining them
- Single-stream architectures that jointly encode the visual and language inputs
Additionally, the authors explore different pre-training tasks beyond just image-text matching, such as:
- Predicting relevant words for a given image
- Generating captions for images
- Aligning visual and language representations
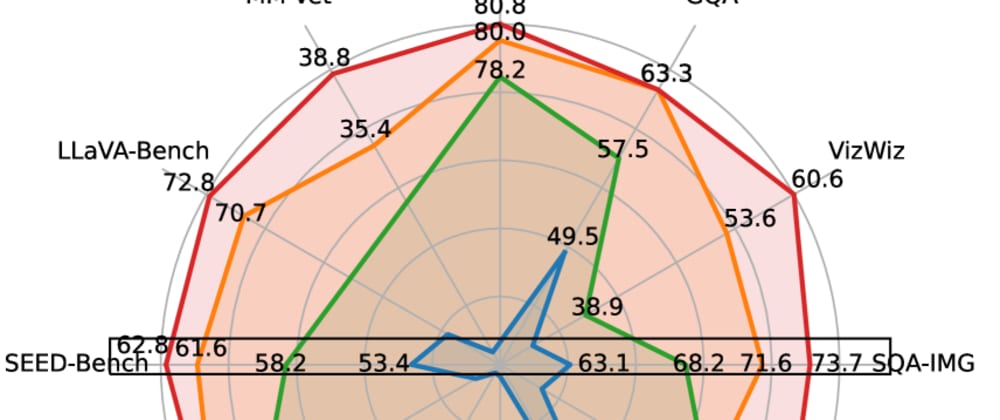
The paper presents extensive experiments comparing these different model designs and pre-training setups on a range of vision-language benchmarks. The results demonstrate that the VILA framework can lead to significant performance improvements, highlighting the value of comprehensive pre-training for vision-language models.
Critical Analysis
The VILA paper makes a valuable contribution by systematically exploring how to effectively pre-train vision-language models. The authors' focus on expanding the pre-training data and tasks is well-motivated, as prior research has shown the importance of rich multimodal representations for these models.
That said, the paper does not delve deeply into the underlying reasons why certain architectural choices or pre-training approaches work better than others. More analysis on the specific inductive biases and learning dynamics introduced by the different model designs and pre-training setups could provide additional insights.
Additionally, the paper does not address potential limitations or negative societal impacts of the VILA framework. As vision-language models become more capable, it will be important to carefully consider issues like biases, privacy, and ethical deployment.
Overall, the VILA paper represents a promising step forward in advancing the state-of-the-art in vision-language pre-training. Further research building on this work could lead to even more capable and robust multimodal models.
Conclusion
The VILA paper introduces a framework for more comprehensive pre-training of vision-language models. By exploring diverse architectural choices and pre-training tasks, the researchers demonstrate significant performance gains on a range of vision-language benchmarks.
This work highlights the importance of rich multimodal representations for tasks that involve both visual and language understanding. As vision-language models continue to grow in capability, the VILA approach could help unlock new applications and insights at the intersection of computer vision and natural language processing.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.


















